What's That Noise?! [Ian Kallen's Weblog]
 Thursday December 03, 2009
Thursday December 03, 2009
Scaling Rails with MySQL table partitioning
![]() Often the first step in scaling MySQL back-ended web applications is integrating a caching layer to reduce the frequency of expensive database queries. Another common pattern is to denormalize the data and index to optimize read response times. Denormalized data sets solve the problem to a point, when the indexes exceed reasonable RAM capacities (which is easy to do with high data volumes) these solutions degrade. A general pattern for real time web applications is the emphasis on recent data, so keeping the hot recent data separate from the colder, larger data set is fairly common. However, purging denormalized data records that have aged beyond usefulness can be expensive. Databases will typically lock records up, slow or block queries and fragment the on-disk data images. To make matters worse, MySQL will block queries while the data is de-fragmented.
Often the first step in scaling MySQL back-ended web applications is integrating a caching layer to reduce the frequency of expensive database queries. Another common pattern is to denormalize the data and index to optimize read response times. Denormalized data sets solve the problem to a point, when the indexes exceed reasonable RAM capacities (which is easy to do with high data volumes) these solutions degrade. A general pattern for real time web applications is the emphasis on recent data, so keeping the hot recent data separate from the colder, larger data set is fairly common. However, purging denormalized data records that have aged beyond usefulness can be expensive. Databases will typically lock records up, slow or block queries and fragment the on-disk data images. To make matters worse, MySQL will block queries while the data is de-fragmented.
MySQL 5.1 introduced table partitioning as a technique to cleanly prune data sets. Instead of purging old data and the service interruptions that a DELETE operation entails, you can break up the data into partitions and drop the old partitions as their usefulness expires. Furthermore, your query response times can benefit from knowing about how the partitions are organized; by qualifying your queries correctly you can limit which partitions get accessed.
But MySQL's partition has some limitations that may be of concern:
- The partitioning criteria must be an integer value. It's easy to express date information as integer values for the purposes of partitioning and in fact you can (albeit intrusively) partition with non integer values using triggers. But the underlying partitioning that MySQL implemented mandates integer criteria.
- All columns used in the partitioning expression for a partitioned table must be part of every unique key that the table may have. This will impact your design as to your use of primary keys and unique keys.
When we first looked at MySQL's table partitioning, this seemed like a deal breaker. The platform we've been working with was already on MySQL 5.1 but it was also a rails app. Rails has its own ORM semantics that uses integer primary keys. What we wanted were partitions like this:
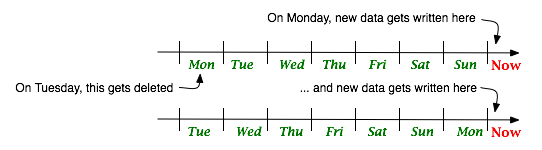
Here, data is segmented into daily buckets and as time advances, fresh buckets are created while old ones are discarded. Yes, with some social web applications, a week is the boundary of usefulness that's why there are only 8 buckets in this illustration. New data would be written to the "Now" partition, yesterday's data would be in yesterday's bucket and last Monday's data would be in the "Monday" bucket. I initially thought that the constraints on MySQL's partitioning criteria might get in the way; I really wanted the data partitioned by time but needed to partition by the primary keys (sequential integers) that rails used like this:
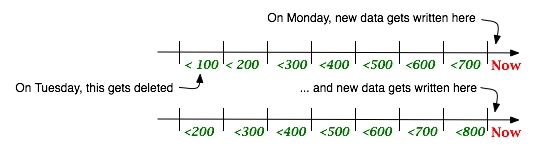
In this case, data is segmented by a ceiling on the values allowed in each bucket. The data with ID values less than 100 go in the first bucket, less than 200 in the second and so on.
Consider an example, suppose you had a table like this:
CREATE TABLE tweets ( id bigint(20) unsigned NOT NULL AUTO_INCREMENT, status_id bigint(20) unsigned NOT NULL, user_id int(11) NOT NULL, status varchar(140) NOT NULL, source varchar(24) NOT NULL, in_reply_to_status_id bigint(20) unsigned DEFAULT NULL, in_reply_to_user_id int(11) DEFAULT NULL, created_at datetime NOT NULL, PRIMARY KEY (id), KEY created_at (created_at), KEY user_id (user_id) );You might want to partition on the "created_at" time but that would require having the "created_at" field in the primary key, which doesn't make any sense. I worked around this by leveraging the common characteristic of rails' "created_at" timestamp and integer primary key "id" fields: they're both monotonically ascending. What I needed was to map ID ranges to time frames. Suppose we know, per the illustration above, that we're only going to have 100 tweets a day (yes, an inconsequential data volume that wouldn't require partitioning, but for illustrative purposes), we'd change my table like this:
ALTER TABLE tweets PARTITION BY RANGE (id) ( PARTITION tweets_0 VALUES LESS THAN (100), PARTITION tweets_1 VALUES LESS THAN (200), PARTITION tweets_2 VALUES LESS THAN (300), PARTITION tweets_3 VALUES LESS THAN (400), PARTITION tweets_4 VALUES LESS THAN (500), PARTITION tweets_5 VALUES LESS THAN (600), PARTITION tweets_6 VALUES LESS THAN (700), PARTITION tweets_maxvalue VALUES LESS THAN MAXVALUE );When the day advances, it's time create a new partition and drop the old one, so we do this:
ALTER TABLE tweets REORGANIZE PARTITION tweets_maxvalue into ( PARTITION tweets_7 VALUES LESS THAN (800), PARTITION tweets_maxvalue VALUES LESS THAN MAXVALUE ); ALTER TABLE tweets DROP PARTITION tweets_0;Programmatically determining what the new partition name should be (tweets_7) requires introspecting on the table itself. Fortunately, MySQL has metadata about tables and partitions in its "information_schema" database. We can query it like this
SELECT partition_ordinal_position AS seq, partition_name AS part_name, partition_description AS max_id FROM information_schema.partitions WHERE table_name='tweets' and table_schema='twitterdb' ORDER BY seq
So that's the essence of the table partition life-cycle. One issue here is that when we reorganize the partition, it completely rewrites it; it doesn't atomically rename "tweets_maxvalue" to "tweets_7" and allocate a new empty "tweets_maxvalue" (that would be nice). If the partition is populated with data, the rewrite is resource consumptive; the more data, the more so. The availability of a table that has a moderate throughput of data (let's say 1 million records daily, not 100) would suffer, locking the table for a long duration waiting for the rewrite is unacceptable for time sensitive applications. Given that issue, what we really want is to anticipate the ranges and reorganize the MAXVALUE partition in advance. When we allocate the new partition, we set an upper boundary on the ID values for but we need to make a prediction as to what the upper boundary will be. Fortunately, we put an index on created_at so we can introspect on the data to determine the recent ID consumption rate like this:
SELECT UNIX_TIMESTAMP(created_at),MAX(id) FROM tweets WHERE DATE(created_at)=DATE( now() - interval 1 day ); SELECT UNIX_TIMESTAMP(created_at),MAX(id) FROM tweets WHERE DATE(created_at)=DATE( now() - interval 2 day ); SELECT UNIX_TIMESTAMP(created_at),MAX(id) FROM tweets WHERE DATE(created_at)=DATE( now() - interval 3 day ); SELECT UNIX_TIMESTAMP(created_at),MAX(id) FROM tweets WHERE DATE(created_at)=DATE( now() - interval 4 day );The timestamps (epoch seconds) and ID deltas give us what we need to determine the ID consumption rate N; the new range to allocate is simply max(id) + N.
OK, so where's the rails? All of this so far has been transparent to rails. To take advantage of the partition access optimization opportunities mentioned above, it's useful to have application level knowledge of the time frame to ID range mappings. Let's say we just want recent tweets from a user M and we know that the partition boundary from a day ago is N, we can say
Tweet.find(:all, :conditions => ["user_id = M AND id > N"])This will perform better than the conventional (even if we created an index on user_id and created_at).
Tweet.find(:all, :conditions => ["user_id = M AND created_at > now() - interval 1 day"])Scoping the query to a partition in this way isn't unique to rails (or even to MySQL, with Oracle we can explicitly name the partitions we want a query to hit in SQL). Putting an id range qualifier in the WHERE clause of our SQL statements will work with any application environment. I chose to focus on rails here because of the integer primary keys that rails requires and the challenge that poses. To really integrate this into your rails app, you might create a model that has the partition metadata.
I hope this is helpful to others who are solving real time data challenges with MySQL (with or without rails), I didn't turn up much about how folks manage table partitions when I searched for it. There's an interesting article about using the MySQL scheduler and stored procedures to manage partitions but I found the complexity of developing, testing and deploying code inside MySQL more of a burden than I wanted to carry, so I opted to do it all in ruby and integrate it with the rails app. If readers have any better techniques for managing MySQL table partitions, please post about it!
Table partitioning handles a particular type of data management problem but it won't answer all of our high volume write capacity challenges. Scaling write capacity requires distributing the writes across independent indexes, sharding is the common technique for that. I'm currently investigating HBase, which transparently distributes writes to Hadoop data nodes, possibly in conjunction with an external index (solr or lucene), as an alternative to sharding MySQL. Hadoop is sufficiently scale free for very large workloads but real time data systems has not been its forte. Perhaps that will be a follow up post.
Further Reading:
Comments [1]
Comments are closed for this entry.



![[Valid RSS]](/images/valid-rss.png "Validate my RSS feed")
Posted by Ian Kallen on December 08, 2009 at 02:20 PM PST #