What's That Noise?! [Ian Kallen's Weblog]
 Thursday December 25, 2008
Thursday December 25, 2008
Downturn, what downturn?
 Just the other day, Data Center Knowledge asked Are Colocation Prices Heading Higher? My immediate reaction was, that's a stupid question: last time VC funding went into hibernation, data center space was suddenly cheap and abundant. The article suggested that companies operating their own data centers will run to the colos as a cost cutting measure. Maybe, but I'm not so sure. Data center migrations can be expensive, risky operations. Methinks that the F500's inclined to undertake a migration would have done so already. The article cited a report emphasizing a shift from capital expenses to operating expenses.
Just the other day, Data Center Knowledge asked Are Colocation Prices Heading Higher? My immediate reaction was, that's a stupid question: last time VC funding went into hibernation, data center space was suddenly cheap and abundant. The article suggested that companies operating their own data centers will run to the colos as a cost cutting measure. Maybe, but I'm not so sure. Data center migrations can be expensive, risky operations. Methinks that the F500's inclined to undertake a migration would have done so already. The article cited a report emphasizing a shift from capital expenses to operating expenses.
Tier 1 says demand for data center space grew 14 percent over the past 12 months, while supply grew by just 6 percent, "exacerbating an already lopsided supply/demand curve."However, Tier 1 attributed the demand, "especially, (to) the primacy of the Internet as a vehicle for service and application delivery." With the litany of Techcrunch deadpool reports, I'm finding it difficult to believe that the data center space supply/demand will continue skewing.
Sure, it's not all bad news. Fred Wilson reports that Union Square Ventures will be Investing In Thick and Thin. Acknowledging that, "it is easier to invest in thin times. The difficult business climate starts to separate the wheat from the chaff and the strong companies are revealed." Wilson goes on to say
I don't feel that its possible, or wise, or prudent to attempt to time these (venture investment) cycles.Yes, the economy is gyrating in pain, but the four horsemen aren't galloping nearby. So take a pill, catch your breath and deal with it: the sun will come out, just don't bother trying to time it too carefully.
Our approach is to manage a modest amount of capital (in our case less than $300 million across two active funds) and deploy it at roughly $40 million per year, year in and year out no matter what part of the cycle we are in.
That way we'll be putting out money at the top of the market but also at the bottom of the market and also on the way up and the way down. The valuations we pay will average themselves out and this averaging allows us to invest in the underlying value creation process and not in the market per se.
Now, there's no shortage of reasons for gloom and doom: mega-ponzi schemes collapsing, banks and real estate combusting, the big 3 in various states of failure, yet BMW North America will raise list prices 0.7%. Before the complete credit breakdown, real estate volume was actually rising in a lot of places (ergo: prices were aligning supply and demand). I was at a William-Sonoma store in Albuquerque the other day, the place was mobbed. My point is that while the economy is retrenching (or the country is rebooting), the detritus will be separated (Wilson's wheat from chaff) and data center space should be cheap and abundant. Everything seems fine to me. At least until the next bubble.
For those of you observing that sort of thing, Merry Christmas!
colocation data centers economy
( Dec 25 2008, 01:20:14 PM PST ) Permalink
Tuesday December 23, 2008
Another Hadoop-backended Database: CloudBase
![]() This post to one of the Hadoop mailing lists caught my eye, Announcing CloudBase-1.1 release. Wait, wasn't Cloudbase the embedded database company that IBM acquired several years back but ended up donating the product to the Apache Software Foundation as Derby? No, not that Cloudbase. This is apparently another project that aims to provide data warehousing on top of Hadoop.
This post to one of the Hadoop mailing lists caught my eye, Announcing CloudBase-1.1 release. Wait, wasn't Cloudbase the embedded database company that IBM acquired several years back but ended up donating the product to the Apache Software Foundation as Derby? No, not that Cloudbase. This is apparently another project that aims to provide data warehousing on top of Hadoop.
I've been watching the emergence of HBase, Hypertable and most recently the proposed incubation of Facebook's Cassandra with great interest. The first two are modeled from Google's BigTable but all are essentially horizontally scalable column oriented databases. The developers of these systems explicitly steer away having their technologies pegged as relational databases, with the refrain: "We don't do joins." What the CloudBase project aims to do is not model themselves on BigTable but to explicitly support joins between tables built on top of an HDFS cluster. It looks like they've posted extensive documentation and have released a JDBC driver, pretty cool! This is the most interesting database initiative I've seen since GreenPlum announced their support for mapreduce.
Yes, as far as scale-out data analytics, we live in interesting times.
mapreduce hadoop hbase hypertable jdbc cloudbase bigtable derby greenplum
( Dec 23 2008, 04:02:21 PM PST ) PermalinkComments [2]
Sunday December 21, 2008
Python SVN Bindings, Trac and mod_python
![]() I have some code I want to noodle on outside of work. Since I'm on a holiday break, I'm doing a bit of that (yes, this is what I do for fun, so?). In the past, I had used my own private CVS server for those kinds of things but these days, I could just as well live without CVS. I decided to roll a subversion server into my Apache build (the latest Apache + other modules aren't in the yum repositories for my distro, so I roll my own). While I'm putting a subversion server up, why not trac, too? Heh, that's where things got stuck.
I have some code I want to noodle on outside of work. Since I'm on a holiday break, I'm doing a bit of that (yes, this is what I do for fun, so?). In the past, I had used my own private CVS server for those kinds of things but these days, I could just as well live without CVS. I decided to roll a subversion server into my Apache build (the latest Apache + other modules aren't in the yum repositories for my distro, so I roll my own). While I'm putting a subversion server up, why not trac, too? Heh, that's where things got stuck.
When I installed the subversion dependencies (specifically, neon), I just used vanilla build params. After installing subversion, I was surprised that Trac couldn't access it. It turns out that the litmus test was this:
$ python Python ... >>> from svn import core...it failed miserably. Various recompile efforts seemed to move the problem around. I saw a variety of the symptoms described in the Trac-Subversion integration docs troubleshooting section. The missing
gss_delete_sec_context symbol error was apparently the telltale critical one, it originated from neon having been compiled without SSL support. The neon compile config that led to success was
./configure --enable-shared --enable-static --with-ssl=opensslThen the real key was to completely start over with the subversion compile, not just the swig python bindings.
make clean ./configure \ --with-berkeley-db=/usr/local/BerkeleyDB.4.7 \ --prefix=/usr/local \ --with-apxs=/usr/local/httpd2.2.11/bin/apxs \ --with-apr=/usr/local/apr \ --with-apr-util=/usr/local/apr make make swig-py make check-swig-py make install make install-swig-py ldconfigOnly then did the litmus test above pass. One of the things about this setup that is kind of a nuisance is that the python bindings didn't get installed into
site-packages, therefore mod_python was quite unhappy. Also, trac seemed to want to put its eggs in the root directory. So the Apache server's envvars script has these variables exported to work around those issues
PYTHONPATH=/usr/local/lib/svn-python LD_LIBRARY_PATH=/usr/local/lib/svn-python/libsvn PYTHON_EGG_CACHE=/data1/egg_cacheThe result (including the requisite
httpd.conf tweaks) is a working subversion 1.54 and trac 0.11 setup. It was more fiddling for the evening than I'd hoped for and I'm not sure my foibles and remedies were optimal (clearly, I missed an RTFM somewhere) but I hope this resolution helps at least one reader.
Happy Hannukah and winter solstice!
apache mod_python trac neon subversion swig python
( Dec 21 2008, 02:55:24 PM PST ) Permalink
Monday December 15, 2008
World Leader Reflex Tests
 Will Chuck-The-Shoe-At-The-World-Leader be an Olympic sport in the years ahead? Since finishing with dinner this evening, I've found no less than three flash games and a compendium of animated GIF satires.
Will Chuck-The-Shoe-At-The-World-Leader be an Olympic sport in the years ahead? Since finishing with dinner this evening, I've found no less than three flash games and a compendium of animated GIF satires.
- Shoe Attack On President Already Turned Into A Crappy Flash Game (Kotaku)
- Sock and Awe
- The Bush Game
- Iraq Shoe Tosser Guy: The Animated Gifs (Boing Boing)
Sunday December 14, 2008
OpenEdge vs. Net Neutrality vs. CDN
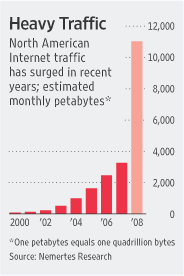 The Wall Street Journal reported today that Google Wants Its Own Fast Track on the Web, describing it as an example of the decline of support for net neutrality amongst the The Powers That Be (the usual suspects: Google, Yahoo, Microsoft, Amazon). Plenty of deals have been getting struck anyway between TPTB and data carriers (most prominently AT&T + Yahoo DSL) but outright transit preference doesn't seem to be an issue here. What Google appears to be getting into, called OpenEdge, sounds like an arrangement that amounts to co-locating their gear in the major carrier's datacenters. This would move serving capacity closer to the end-users of their services and thereby accelerate the user experience. Since it doesn't concern transit per se, this actually doesn't sound like a net neutrality issue at all, it sounds like another form of datacenter dispersion.
The Wall Street Journal reported today that Google Wants Its Own Fast Track on the Web, describing it as an example of the decline of support for net neutrality amongst the The Powers That Be (the usual suspects: Google, Yahoo, Microsoft, Amazon). Plenty of deals have been getting struck anyway between TPTB and data carriers (most prominently AT&T + Yahoo DSL) but outright transit preference doesn't seem to be an issue here. What Google appears to be getting into, called OpenEdge, sounds like an arrangement that amounts to co-locating their gear in the major carrier's datacenters. This would move serving capacity closer to the end-users of their services and thereby accelerate the user experience. Since it doesn't concern transit per se, this actually doesn't sound like a net neutrality issue at all, it sounds like another form of datacenter dispersion.
So what exactly is the big deal? All of the TPTB and loads of other online services have content delivery network (CDN) deals. Yahoo, Amazon, Facebook... they all operate or partner with a CDN in some shape or form (full disclosure: I've been working on a CDN evaluation for Technorati). With a CDN, publishers pay specifically to have their content cached at points-of-presence (PoP) around the intertubes that, through some DNS and routing magic, enables web content to get to end-users more quickly. The next step beyond a CDN is to put equipment in the carrier's datacenter. Here's what WSJ said
Google's proposed arrangement with network providers, internally called OpenEdge, would place Google servers directly within the network of the service providers, according to documents reviewed by the Journal. The setup would accelerate Google's service for users. Google has asked the providers it has approached not to talk about the idea, according to people familiar with the plans.It seems perfectly logical, actually.
Asked about OpenEdge, Google said only that other companies such as Yahoo and Microsoft could strike similar deals if they desired. But Google's move, if successful, would give it an advantage available to very few.
Nonetheless, I am concerned about wavering support for net neutrality. Lawrence Lessig, fresh off of his Big News post concerning setting up shop at Harvard Law School, is quoted as saying
There are good reasons to be able to prioritize traffic. If everyone had to pay the same rates for postal service, than you wouldn't be able to differentiate between sending a greeting card to your grandma versus sending an overnight letter to your lawyer.But the counter argument says that there's a big difference. Grandma isn't trying to compete with your attorney (at least, not usually). If the big guys are paying more to be faster, who will be able afford to challenge them? The intertubularly rich will get richer, the poor will be stay poor. The TPTB will ensconce themselves as dynastic media walking on paths paved with gold while all of us commoners walk in the gutter.
The dumb pipes should stay dumb. If an internet service wants to operate out of multiple datacenters, lease dedicated pipes to accelerate their inter-datacenter data distribution and peer with the carrier's PoPs proximate to their datacenters, mazel tov. This can be augmented with CDNs. It can even be taken to the next step by directly installing the carrier's datacenters. But at the network exchanges and pipes connecting them, everyone's packets should remain equal.
UPDATE GigaOM posted about a clarification from Google which says that the WSJ was "confused". The hubbub in that article really was misplaced, it's a CDN deal.
google cdn content delivery network net neutrality wall street journal
( Dec 14 2008, 10:52:25 PM PST ) PermalinkComments [1]
Wednesday December 10, 2008
Cloud Hype, An Amazon Web Services Post-Mortem
![]() In the last few years, the scope of Amazon Web Services (AWS) has broadened to cover a range of infrastructure capabilities and has emerged as a game changer. The hype around AWS isn't all wrong, a whole ecosystem of tools and services has developed around AWS that makes the offering compelling. However, the hype isn't all right either. At Technorati, we used AWS this year to develop and put in production a new crawler and a system that produces the web page screenshot thumbnails now seen on search result pages. But now that that chapter is coming to a close, it's time to retrospect.
In the last few years, the scope of Amazon Web Services (AWS) has broadened to cover a range of infrastructure capabilities and has emerged as a game changer. The hype around AWS isn't all wrong, a whole ecosystem of tools and services has developed around AWS that makes the offering compelling. However, the hype isn't all right either. At Technorati, we used AWS this year to develop and put in production a new crawler and a system that produces the web page screenshot thumbnails now seen on search result pages. But now that that chapter is coming to a close, it's time to retrospect.
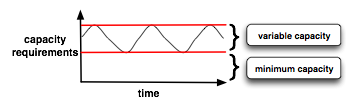 There's a prevailing myth that using the elasticity of EC2 makes it cheaper to operate than fixed assets. The theory is that by shutting down unneeded infrastructure during the lulls, you're saving money. In a purely fixed infrastructure model, Technorati's data aquisition systems must be provisioned for their maximum utilization capacity threshold. When utilization ebbs, a lot of that infrastructure sits relatively idle. That much is true but the reality is that flexible capacity is only saving money relative to the minimum requirements. So the theory only holds if your variability is high compared to your minimum. That is, if the difference between your minimum and maximum capacity is large or you're not operating a 365/7/24 system but episodically using a lot of infrastructure and then shutting it down. Neither is true for us. The normal operating mode of Technorati's data acquisition systems follows the ebb and flow of the blogosphere, which varies a lot but is always on. The sketch to the left shows the minimum capacity and the variable capacity distinguished.
There's a prevailing myth that using the elasticity of EC2 makes it cheaper to operate than fixed assets. The theory is that by shutting down unneeded infrastructure during the lulls, you're saving money. In a purely fixed infrastructure model, Technorati's data aquisition systems must be provisioned for their maximum utilization capacity threshold. When utilization ebbs, a lot of that infrastructure sits relatively idle. That much is true but the reality is that flexible capacity is only saving money relative to the minimum requirements. So the theory only holds if your variability is high compared to your minimum. That is, if the difference between your minimum and maximum capacity is large or you're not operating a 365/7/24 system but episodically using a lot of infrastructure and then shutting it down. Neither is true for us. The normal operating mode of Technorati's data acquisition systems follows the ebb and flow of the blogosphere, which varies a lot but is always on. The sketch to the left shows the minimum capacity and the variable capacity distinguished.
In response to some of the fallacies posted on an O'Reilly blog the other day (by George Reese), On Why I Don't Like Auto-Scaling in the Cloud, Don MacAskill from SmugMug wrote a really great post yesterday about his SkyNet system, On Why Auto-Scaling in the Cloud Rocks. Don also emphasizes SmugMugs modest requirements for operations staff. In an application with sufficient simplicity and automation around it, it's easy to imagine a 365/7/24 service having meager ops burdens. I think we should surmise that the cost of operating SmugMug with autonomic de/provisioning works because it fits their operating model. I understand Reese's concern, that folks may not do the hard work of really understanding their capacity requirements if they're too coddled by automation. However, that concern comes off as a shill for John Allspaw's capacity planning book (which I'm sure is great, can't wait to read it). Bryan Duxbury from RapLeaf describes their use of AWS and how the numbers work out in his post, Rent or Own: Amazon EC2 vs. Colocation Comparison for Hadoop Clusters. Since the target is to serve a Hadoop infrastructure, AWS must get a thumbs down in their case. Hadoop's performance is impaired by poor rack locality and the latencies of Amazon's I/O systems clearly drags it down. If you're going to be running Hadoop on a continuous basis, use your own racks, with your own switches and your own disk spindles.
At Technorati, we're migrating the crawl infrastructure from AWS to our colo. While I love the flexibility that AWS provides and it's been great using it as a platform to ramp up on , the bottom line is that Technorati has a pre-existing investment in machines, racks and colo infrastructure. As much as I'd like our colo infrastructure to operate with lower labor and communication overhead, running on AWS has amounted to additional costs that we must curtail.
Cloud computing (or utility computing or flex computing or whatever its called) is a game changer. So when do I recommend you use AWS? Ideally: anytime. If your application is architected to expand and contract its footprint with the demands put upon it, provision your minimum capcacity requirements in your colo and use AWS to "burst" when your load demands it. Another case where using AWS is a big win is for a total green field. If you don't have a colo, are still determining the operating charactersics of your applications and need machines provisioned, AWS is an incredible resource. However, I think the flexibility vs. economy imperatives will always lead you to optimize your costs by provisioning your minimum capacity in infrastructure that you own and operate.
There's also another option: instead of buying and operating your own machines and racks, you may be able to optimize costs by renting machines provisioned to your specs in a contract from the services that have established themselves in that market (Rackspace, Server Beach, ServePath, LayeredTech, etc). Ultimately, I'm looking forward to the emergence of a compute market place where the decisions to incur capital expense, rent by the hour or rent under a contract will be easier to traverse.
amazon web services aws cloud computing rapleaf technorati smugmug hadoop oreilly data centers capacity planning
( Dec 10 2008, 11:53:19 PM PST ) PermalinkComments [2]
Tuesday December 09, 2008
The Solar Decade
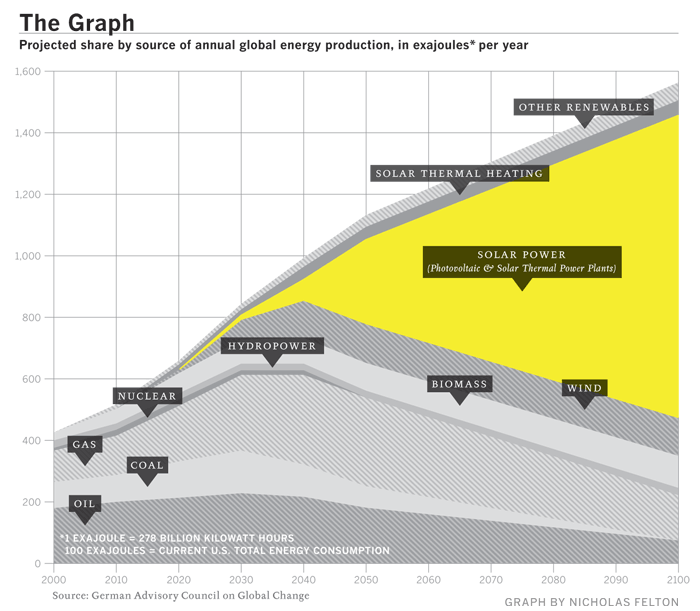 Ten years ago, you might have been advised that solar energy, while sounding nice, was a bad investment. The installations were failure prone and not cost effective. I don't know if I bought that then, I know of solar panels in San Francisco installed in the 80's that paid for themselves, just slowly. But what we're seeing isn't your father's solar panel. From Google's solar panels to residential rooftops, it seems pretty clear that the
Economics of Solar Power Are Looking Brighter. Fast Company is running an article The Solar Industry Gains Ground that sounds a chord that we're hearing a lot of. Solar energy is getting more and more cost effective. What's projected is that the cost of solar power may share up-and-to-the-right properties of Moore's Law. The fabs that make the silicon enabling you to read this may also enable an energy giant leap forward. The Germans have their own "Solar Valley" and their industry projection graph appears pretty Moorish (look at the large yellow area).
Ten years ago, you might have been advised that solar energy, while sounding nice, was a bad investment. The installations were failure prone and not cost effective. I don't know if I bought that then, I know of solar panels in San Francisco installed in the 80's that paid for themselves, just slowly. But what we're seeing isn't your father's solar panel. From Google's solar panels to residential rooftops, it seems pretty clear that the
Economics of Solar Power Are Looking Brighter. Fast Company is running an article The Solar Industry Gains Ground that sounds a chord that we're hearing a lot of. Solar energy is getting more and more cost effective. What's projected is that the cost of solar power may share up-and-to-the-right properties of Moore's Law. The fabs that make the silicon enabling you to read this may also enable an energy giant leap forward. The Germans have their own "Solar Valley" and their industry projection graph appears pretty Moorish (look at the large yellow area).
The big lift off is 10 years away but the investment that has been made in the area and the advances being made seem to put the benefits close at hand. But the big win, when dependence on fossil fuels are on a clear decline, is at leat 10 and 20 years out. But I think it can happen, I think the solar decade is coming. It should be the coming decade. However, it will require an Apollo-mission like focus from the Obama administration to succeed. And I hope we can make it a reality.
( Dec 09 2008, 11:55:24 PM PST ) Permalink
Monday December 08, 2008
Good Bye, Perl
![]() The other day, I was patching some Perl code. There I was, in the zone, code streaming off of my finger tips. But wait, I was writing Python in the middle of a Perl subroutine. Um. I found the bare word and missing semi-colon errors invoking
The other day, I was patching some Perl code. There I was, in the zone, code streaming off of my finger tips. But wait, I was writing Python in the middle of a Perl subroutine. Um. I found the bare word and missing semi-colon errors invoking perl -cw dingleberry.pl amusing. How did that happen?
Truth is, I find myself rarely using Perl anymore. I spent years building applications with Perl. Having made extensive use of mod_perl APIs and various CPAN modules, studied the Talmudic wisdom of Damian Conway, struggled with the double-edged sword of TMTOWTDI and rolled my eyes at the Perl haters for their failure to appreciate the strange poetry that is Perl it'd seem like a safe bet that Perl would remain on my top shelf. A lot of the complaints of Perl haters seem superficial ("ewe, all of those punctuation characters", shaddup). Yet, Perl has been long in the tooth, for a long time. I recall 5 years ago thinking that Perl 6 wasn't too far away (after all, O'Reilly published Perl 6 Essentials in June 2003). I'm sorry, my dear Perl friends, insistence that Perl is Alive rings hollow, now.
I still find it heartening to hear of people doing cool things with Perl. David McLaughlin's uplifting How I learnt to love Perl, waxing on about Moose and other "modern" Perl frameworks (but come on dude, everyone knows that PHP, sucks, heh). Brad Fitzpatrick released Perl for Google App Engine today. But Perl, I'm sorry. It's just too little, too late.
I'm just weary of the difficulties achieving team adherence to disciplined coding practices (or even appreciate why they're especially necessary in the TMTOWTDI world of Perl). The reliance on Wizardry is high with Perl; the path from novice to master requires grasping a wide range of arcana. Is it too much to ask for less magic in favor of easier developer ramp up? Perl's flexibility and expressiveness, it's high virtues, also comprises the generous reel of rope that programmers routinely hang themselves with. On top of idiomatic obscurities are the traps people fall into with dynamic typing and errors that only make themselves evident at runtime. Good testing practices are usually the anecdote to the woes of dynamic typing and and yet writing a good test harness for a Perl project is often a lot of work compared to the amount of work required to write the application code.
I well understand the security that programmers feel using static typing but I'm not saying the static typing is the cure to any ills. The compiler is the most basic test that your code can be understood and it gives your IDE a lotta help. That's great but static typing is also an anchor dragging on your time. From what I can tell, Java is the new C/C++ and Jython, JRuby. Groovy and friends (Scala, Clojure, etc) are the ways that people program the JVM with higher productivity. I'm not saying fornever to Perl (that's a long time). But I am saying Hasta La Vista, for now. I've been quite productive lately with Python (I know Perl friends, heresy!) and plan on pushing ahead with that, as well as with Java and other JVM languages. And where necessary, using Thrift to enable the pieces to work together. Python is certainly not perfect, it's quirks are many, too. But I've seen recent success with collaborative software development with Python that would have been difficult to accomplish with Perl. I'm not trying to stoke any language war at all, I'm just reflecting on how I've drifted from Perl. Amongst people I know and things I've read elsewhere, I'm not the only one. Don't fret, Perl, I'm sure I'll see you around.
( Dec 08 2008, 12:01:24 AM PST ) PermalinkComments [7]
Saturday December 06, 2008
MySQL vs. PostgreSQL (again)
![]()
![]() If Kevin Burton wanted to draw attention to MySQL's inattention to scalability concerns, it looks like he's succeeded (126 comments on Reddit in the last day and climbing). I totally understand why he feels that the MySQL folks need to be provoked into action. I'll confess to having serious "MySQL fatigue" after years of struggling with InnoDB quirks (we use MySQL extensively at Technorati), stupid query plans and difficult to predict performance inflection points (there's a calculus behind table row count, row width, number of indices, update rate and query rate -- but AFAIK nobody has a reliable formula to predict response times against those variables). Frankly, I was really surprised when Sun acquired MySQL (for such a hefty sum, too), I was expecting them to build up a PostgreSQL-based platform by rolling up acquisitions of Greenplum and Truviso.
If Kevin Burton wanted to draw attention to MySQL's inattention to scalability concerns, it looks like he's succeeded (126 comments on Reddit in the last day and climbing). I totally understand why he feels that the MySQL folks need to be provoked into action. I'll confess to having serious "MySQL fatigue" after years of struggling with InnoDB quirks (we use MySQL extensively at Technorati), stupid query plans and difficult to predict performance inflection points (there's a calculus behind table row count, row width, number of indices, update rate and query rate -- but AFAIK nobody has a reliable formula to predict response times against those variables). Frankly, I was really surprised when Sun acquired MySQL (for such a hefty sum, too), I was expecting them to build up a PostgreSQL-based platform by rolling up acquisitions of Greenplum and Truviso.
Kevin is totally correct that to find solid innovation with MySQL, don't look to the MySQL corporation. Instead, the consultants and third party shops specializing in MySQL are where the action's at (Palomino DB, Percona, Drizzle, etc). It's kinda sad, both Sun and MySQL have at various times been home to hot-beds of innovation. Sun has great people groundbreaking with cloud computing, impressive CPU performance per watt improvements and the Java ecosystem. But as far as MySQL goes, look to the outside practitioners.
Kevin's post update cites the pluggable back-ends that MySQL supports as a feature but I'm not so sure. I don't have any evidence of this but my intuition is that it's exactly this feature that makes the overall stability and performance such a crap-shoot (or sometimes, just outright crap). I'm working on a personal project that uses PostGIS (PostgreSQL + GIS), nothing is live yet so I haven't had to scale it. But I have a good deal of confidence in the platform. Skype and Pandora look like good case studies. The PostgreSQL people have been focused on MVCC concurrency, procedure languages, UDFs and data integrity semantics for years. In those realms, the MySQL people are Johnny-come-slowlies (and buggily). On the other hand, if you want the append-only characteristics of logging to a database, MyISAM and merge tables have performance properties that PostgreSQL just can't match.
Maybe David Duffield will look beyond enterprise app services and acquire, roll-up and market the PostgreSQL platforms that Sun didn't. Combining big data and event data with Greenplum and Truviso as a way to blow some smoke in Larry Ellison's eye, that would be funny (and smart).
postgresql mysql greenplum truviso sun workday postgis
( Dec 06 2008, 12:08:20 PM PST ) Permalink
Friday December 05, 2008
It's Only The Biggest Country In the World
 Should the confirmed reports that Technorati is banned in China be worn as a badge honor? I understand the Chinese authorities value stability but these kinds of things, treating billions of people like little children that need to be sheltered, will ultimately destabilize them.
Should the confirmed reports that Technorati is banned in China be worn as a badge honor? I understand the Chinese authorities value stability but these kinds of things, treating billions of people like little children that need to be sheltered, will ultimately destabilize them.
We've waited 18 years for Chinese Democracy, isn't that long enough? (sorry, couldn't resist the joke)
Best wishes to the Chinese people. At least most of you.
chinese democracy china censorship technorati guns n roses
( Dec 05 2008, 06:12:19 PM PST ) Permalink
Thursday December 04, 2008
Technorati Releases Fixes Some UI Peeves
![]() In general, I regard successful user interfaces as the ones that provide the least amount of hunting and astonishment. Noone is delighted when the things they're looking for aren't obvious, the data displayed requires lots of explanation and the paths through an application are click-heavy. In this regard, Technorati was long saddled with a user interface that I regarded as delightless. However, I see that changing now and I'm delighted to see that!
In general, I regard successful user interfaces as the ones that provide the least amount of hunting and astonishment. Noone is delighted when the things they're looking for aren't obvious, the data displayed requires lots of explanation and the paths through an application are click-heavy. In this regard, Technorati was long saddled with a user interface that I regarded as delightless. However, I see that changing now and I'm delighted to see that!
Technorati's front end was released today with a handful of significant improvements. One is a long standing peeve of mine: the tag pages we're conflated with keyword search. That meant that if your post was about the president-elect and you tagged it "obama", your expectation that the the posts aggregated at http://technorati.com/tag/obama would also be tagged "obama" would be disappointed; there would also be a bunch of keyword matches mixed in. That came out of last year's attempt to "simplify" the experience by making keyword search and tag browsing the same thing; which was, in all honesty, a George Bush level failure. Sure there are folks who don't know, "What's this 'tag' thing you're talking about?" But for the folks who do know what the difference is between browsing blog posts grouped by tags and keyword search results, the mix wasn't received as a simplification but as a software defect.
I tagged my post "obama" but all of these other posts aren't tagged "obama", what's going on?I'm glad we've gone back to keeping search and tags distinct.
The other failed aspect of the prior design was the demotion of the search box. The form input to type in your search was sized down and moved to the right, as if it were a "site search" feature. Yes, we'd like folks to explore our discovery features but the navigation for those features weren't great and the de-emphasis on search was again a source of more puzzlement than anything. The release today puts the search box back where it should be: bigger and right in the middle of the of the top third of the page, yay!
Oh, and earlier today Technorati Media released its Engage platform to beta. This is a major step in opening up the ad market place for the blogosphere.
So far, the feedback I've seen on these releases have been thumbs-up. Check 'em out, there's some more goodies in the works but these things only get better with your feedback. And yes, we know there's still more to do, I'm certainly busy with the backend stuff with our cloud platform, ping systems and crawlers (but did you notice the screenshot thumbnails on the search result and tag pages? I need to shake out the latencies producing and refreshing those). Kudos to Dave White, the front end team and the ad platform team for getting these releases out. Onward and upward!
technorati folksonomy tagging user interface blogging ad platform
( Dec 04 2008, 06:43:39 PM PST ) PermalinkComments [2]
Wednesday December 03, 2008
Can We Just Call It "Flex Computing"?
 The moniker "cloud computing" has been overloaded to mean to so many things, it's beginning to mean nothing. When someone refers to it generically, you have to ask them to dismbiguate; which of these are they referring to?
The moniker "cloud computing" has been overloaded to mean to so many things, it's beginning to mean nothing. When someone refers to it generically, you have to ask them to dismbiguate; which of these are they referring to?
- IT infrastructure offered as a services
- Hosted application functionality
- A virtualized server deployment
Examples of the first definition are services like Amazon Web Services (AWS) or GoGrid. They provide metered virtual machines, you pay for what you use and have full access (root) on the machines while you use them. Additional goodies such as load balanced clusters, storage facilities and so forth are part of the deal too. Capacity can be scaled up or down on demand and typically, in very rapid fashion. When Peter Wayner reviewed these guys last summer in InfoWorld, he was enamored with the GUI front ends. Call me old fashioned (or a dyed in the wool geek) but unless they're really saving me a lot of time, I have an aversion to the slick GUI's. For his part, Wayner complained about the AWS command line utilities. Actually, when I use AWS, I use a GUI for an overview of running instances, it's a Firefox plugin (Elasticfox) but what I really like about AWS is programmatic access. Integrating application deployment with command and control functionality is very powerful, my tool of choice is boto, a Python API for AWS.
The second definition refers to hosted application functionality, in years gone by they were referred to as Application Service Providers (ASP). The more modern label is Software as a Service (SaaS). However, these services have to provide more than a console for functionality, they have to provide web service API's that enable them to be integrated into other applications. SalesForce.com was an early leader in this space (remember the red cross-outs, "No Software"), their example and the proliferation of RSS is really want inspired the proliferation of APIs and mashups we see today.
The last definition refers to VMWare, Xen and so forth. By themselves, those aren't really cloud computing in my book. However, you can use them to create your own "private cloud" with tools like Enomaly and Eucalyptus. This is an area of great interest to me.
In his review, Wayner pointed out how very different all of the services are. I don't know why he included Google's App Engine at all in his write-up. Don't misunderstand, GAE is a great service but it more closely resembles an application container than infrastructure services.
I'm imagining IT infrastructure management interfaces coalescing around standards (de-facto ones, not ones fashioned out of IETF meetings). Eucalyptus is a good discussion point. Eucalyptus provides an EC2 "work-alike" interface on top of a Xen virtual server platform. So picture this: if the Rackspaces, ServePaths, Server Beaches and LayeredTechs of this world were to provide a compatible interfaces built on top of Eucalyptus, buying compute power by the hour would become more like buying gasoline. There may be pros and cons to this station or that but fundamentally, if you don't like the pumps at one gas station or the prices are too high, you can go to the gas station across the street. Given compatible interfaces, management of the infrastructure, be it with boto, Elasticfox or using services such as RightScale can be as dynamic as the server deployments in those clouds. Such a compute market place would unleash new rounds of innovation as it eases starting up and scaling online services.
The Eucalyptus folks will be the first to fess up that their project is more academic in nature that industrial strength. However, it is the harbinger of AWS as a standard. Yes, I'm referring to AWS as a standard because of the level of adoption its enjoyed, the comprehensive set of APIs it provides and the rich ecosystem around it. What I foresee is that the first vendor to embrace and commoditize a standard interface for infrastructure management changes the game. The game becomes one of a meta-cloud because computing capacity will be truly fluid, flexibly shrinking and growing with hosted clouds, private clouds and migrating between clouds.
cloud computing saas virtualization aws xen
( Dec 03 2008, 10:44:46 PM PST ) PermalinkComments [3]
Tuesday December 02, 2008
Social Media Backlash Against Cheaters and Fleshmongers
 As long as there is any media, pornographers will figure out how use it to purvey their wares. The other week, I mentioned on the Technorati blog that I'd been focusing on some spam scrubbing efforts, including removing porn. Apparently we're not the only social media service taking a look at the bottom line impact of miscreant activities. A few related items of interest percolated recently.
As long as there is any media, pornographers will figure out how use it to purvey their wares. The other week, I mentioned on the Technorati blog that I'd been focusing on some spam scrubbing efforts, including removing porn. Apparently we're not the only social media service taking a look at the bottom line impact of miscreant activities. A few related items of interest percolated recently.
Social network service provider Ning announced their End of the Red Light District. The high infrastructure costs, lack of revenue and administrative burdens (DMCA actions) were among the reasons cited. Sounds very familiar, we get our share of that kind of pointless nonsense at Technorati too.
Today, YouTube posted that they were going to crack down or reduce the visibility of porny videos. YouTube's measures include
- Stricter standard for mature content
- Demotion of sexually suggestive content and profanity
- Improved thumbnails
As expected in these cases, the trolls come out to cry foul. But this isn't about free speech or puritan ethics, the issue more closely resembles the tragedy of the commons. It's really very simple: these parasitic uses consume a lot of resources but bring no benefits to the host and degrade the service for other users.
Also today, Digg Bans Company That Blatantly Sells Diggs was reported by Mashable. Apparently Digg has directed a cease-and-desist at USocial.net's practice of selling diggs.
It seems to be an accepted truism that social media oft demonstrates, All Complex Ecosystems Have Parasites. Yep, I've talked to folks from Six Apart, Wordpress, Tumblr, Twitter and elsewhere. We're all feeling the pains of success. Over the past month at Technorati, we've purged about 80% of the porn that was active in the search index. Sure, we're not spam free yet but the index is getting a lot cleaner.
technorati digg youtube ning porn spam
( Dec 02 2008, 11:42:34 PM PST ) PermalinkComments [2]
Monday December 01, 2008
System Gaming and Its Consequences
![]() Technorati's authority metric is based on a real simple concept: the count of the unique set of blogs linking to you in the trailing 180 days constitutes your authority. By its very nature, it's a volatile metric. The top 100 of a few years ago bears little resemblance to the one today. When some folks observe their authority rising, they twitter w00ts of joy; when it's falling they complain bitterly that Technorati is "downgrading" them.
Technorati's authority metric is based on a real simple concept: the count of the unique set of blogs linking to you in the trailing 180 days constitutes your authority. By its very nature, it's a volatile metric. The top 100 of a few years ago bears little resemblance to the one today. When some folks observe their authority rising, they twitter w00ts of joy; when it's falling they complain bitterly that Technorati is "downgrading" them.
Authority is not a perfect metric (crawl coverage variations, etc) nor the only important measurement of a blog (traffic and comments are other metrics we'd like to measure), however it is one that Technorati has been objectively calculating for years.
What I find surprising is the surprise (or denial) that some people find when they learn there are consequences to gaming the system. On a fairly regular basis, someone comes up with the wholly unoriginal idea, "Hey, add your URL to my list of links, re-post it and urge others to follow suit to make your Technorati authority explode!" Or some variant of a viral link exchanging scheme. Some folks take the news graciously, "Oh, that's not OK? I had no idea. It won't happen again." But some of these folks get downright hostile, as if the blog authority metric is their god given right to game. These are probably the same people who expect appreciation on their home's property value to be a god given right. News flash: it's not. Since it's (apparently for some) not obvious: the attention you garner in the blogosphere and the price someone will pay for your house are driven by market forces. If your authority is dropping, create posts that are link-worthy. There's no shortcut. Blogs engaging in viral linking schemes stand a good chance that indexing will be suspended or the blog removed altogether from Technorati's index.
Use the blogosphere to converse, to entertain, to teach and to learn. We'll do our best to measure it and to build applications with those measurements. If you want to play games, get a Wii.
( Dec 01 2008, 10:40:34 PM PST ) Permalink


![[Valid RSS]](/images/valid-rss.png "Validate my RSS feed")