What's That Noise?! [Ian Kallen's Weblog]
 Saturday April 30, 2011
Saturday April 30, 2011
The mobile web, bookmarks and the apps they should be able to play with
 Last year Marco Arment of Instapaper and Tumblr fame posted a plea to Apple with an open enhancement request to the Mobile Safari team for sane bookmarklet installation or alternatives. In it he detailed how mobile browsers such as mobile Safari on iPhones and iPads are second class citizens on the web. You can't build plug-ins for them or easily add bookmarklets (javascript you can invoke from the browser's bookmarks). Instapaper on iOS devices would greatly benefit from easier integration into with the device's browser. I went through the bookmarklet copy/paste exercise that Instapaper walks you through, it's definitely a world of pain. Well, I read this morning that it looks like Apple is answering him, perhaps. Maybe backhanding him.
Last year Marco Arment of Instapaper and Tumblr fame posted a plea to Apple with an open enhancement request to the Mobile Safari team for sane bookmarklet installation or alternatives. In it he detailed how mobile browsers such as mobile Safari on iPhones and iPads are second class citizens on the web. You can't build plug-ins for them or easily add bookmarklets (javascript you can invoke from the browser's bookmarks). Instapaper on iOS devices would greatly benefit from easier integration into with the device's browser. I went through the bookmarklet copy/paste exercise that Instapaper walks you through, it's definitely a world of pain. Well, I read this morning that it looks like Apple is answering him, perhaps. Maybe backhanding him.
Apple is apparently implementing their own "Reading List" feature that current speculation says is squarely aimed at Instapaper and Read It Later. This came out of a MacRumors report on early builds of Lion, the next version of Mac OS X. VentureBeat rightly supposes there will be complimentary features on iOS devices.
Like Marco, I'd like to be able to build apps that run natively on devices that can play more smoothly with the device's browser. While mobile SDKs may have support for running an embedded browser (AKA "web views") they're still crippled by having the main browser in it's own silo (and has been previously circulated, web view javascript engines are crippled in their own). Ideally what we're seeing isn't an assault on existing bookmark services but the harbinger of API's that will allow developers to integrate more of the browser's functionality. Certainly some things should continue to be closely sandboxed (e.g. browsing history visibility) or requires full disclosure and permission (e.g. access to the cookie jar). Privacy leaks, phishing attacks and other sorts of miscreant behavior should obviously be guarded against but bookmark additions seem like an easy thing to provide an API and safe user experience around.
As Delicious (and before them, Backflip RIP and good riddance) showed, bookmarks are significant social objects. Bookmarks are also a significant personal utility, much like an address book or calendar. I've often considered building an Instapaper or Read It Later type of app, I can't count the number of times I've found something I've wanted to read but didn't have time to read it that instance. Numerous efforts to build interesting things with bookmarks have risen and fallen (ma.gnolia.com) or stalled (sigh... xmarks, simpy). I'm convinced that the emergence of the mobile web and the native app ecosystems that play with them will create an abundance of new opportunities. But developers need to be enabled. Apple, please give us API's, not more silos!
( Apr 30 2011, 09:22:48 AM PDT ) Permalink
Sunday January 16, 2011
Managing Granular Access Controls for S3 Buckets with Boto
![]() Storing backups is a long-standing S3 use case but, until the release of IAM the only way to use S3 for backups was to use the same credentials you use for everything else (launching EC2 instances, deploying artifacts from S3, etc). Now with IAM, we can create users with individual credentials, create user groups, create access policies and assign policies to users and groups. Here's how we can use boto to create granular access controls for S3 backups.
Storing backups is a long-standing S3 use case but, until the release of IAM the only way to use S3 for backups was to use the same credentials you use for everything else (launching EC2 instances, deploying artifacts from S3, etc). Now with IAM, we can create users with individual credentials, create user groups, create access policies and assign policies to users and groups. Here's how we can use boto to create granular access controls for S3 backups.
So let's create a user and a group within our AWS account to handle backups. Start by pulling and installing the latest boto release from github. Let's say you have an S3 bucket called "backup-bucket" and you want to have a user whose rights within your AWS infrastructure is confined to putting, getting and deleting backup files from that bucket. This is what you need to do:
- Create a connection to the AWS IAM service:
import boto iam = boto.connect_iam()
- Create a user that will be responsible for the backup storage. When the credentials are created, the access_key_id and access_key_id components of the response will be necessary for the user to use them, save those values:
backup_user = iam.create_user('backup_user') backup_credentials = iam.create_access_key('backup_user') print backup_credentials['create_access_key_response']['create_access_key_result']['access_key']['access_key_id'] print backup_credentials['create_access_key_response']['create_access_key_result']['access_key']['secret_access_key'] - Create a group that will be assigned permissions and put the user in that group:
iam.create_group('backup_group') iam.add_user_to_group('backup_group', 'backup_user') - Define a backup policy and assign it to the group:
backup_policy_json="""{ "Statement":[{ "Action":["s3:DeleteObject", "s3:GetObject", "s3:PutObject" ], "Effect":"Allow", "Resource":"arn:aws:s3:::backup-bucket/*" } ] }""" created_backup_policy_resp = iam.put_group_policy('backup_group', 'S3BackupPolicy', backup_policy_json)
Note: the AWS_ACCESS_KEY_ID and AWS_SECRET_ACCESS_KEY environment variables need to be set or they need to be provided as arguments to the boto.connect_iam() call (which wraps the boto.iam.IAMConnection ctor).
Altogether Now:
import boto
iam = boto.connect_iam()
backup_user = iam.create_user('backup_user')
backup_credentials = iam.create_access_key('backup_user')
print backup_credentials['create_access_key_response']['create_access_key_result']['access_key']['access_key_id']
print backup_credentials['create_access_key_response']['create_access_key_result']['access_key']['secret_access_key']
iam.create_group('backup_group')
iam.add_user_to_group('backup_group', 'backup_user')
backup_policy_json="""{
"Statement":[{
"Action":["s3:DeleteObject",
"s3:GetObject",
"s3:PutObject"
],
"Effect":"Allow",
"Resource":"arn:aws:s3:::backup-bucket/*"
}
]
}"""
created_backup_policy_resp = iam.put_group_policy('backup_group', 'S3BackupPolicy', backup_policy_json)
While the command line tools for IAM are OK (Eric Hammond wrote a good post about them in Improving Security on EC2 With AWS Identity and Access Management (IAM)), I really prefer interacting with AWS programmatically over remembering all of the command line options for the tools that AWS distributes. I thought using boto and IAM was blog-worthy because I had a hard time discerning the correct policy JSON from the AWS docs. There's a vocabulary for the "Action" component and a format for the "Resource" component that wasn't readily apparent but after some digging around and trying some things, I arrived at the above policy incantation. Aside from my production server uses, I think IAM will make using 3rd party services that require AWS credentials to do desktop backups much more attractive; creating multiple AWS accounts and setting up cross-account permissions is a pain but handing over keys for all of your AWS resources to a third party is just untenable.
In the meantime, if you're using your master credentials for everything on AWS, stop. Adopt IAM instead! To read more about boto and IAM, check out
( Jan 16 2011, 03:09:15 PM PST ) Permalink
Sunday August 29, 2010
Scala Regular Expressions
![]() I've been using Scala for the past several weeks, so far it's been a win. My use of Scala to date has been as a "better Java." I'm peeling the onion layers of functional programming and Scala's APIs, gradually improving the code with richer Scala constructs. But in the meantime, I'm mostly employing plain old imperative programming. At this point, I think that's the best way to learn it. Trying to dive into the functional programming deep end can be a bit of a struggle. If you don't know Java, that may not mean much but for myself, I'd used Java extensively in years past and the project that I'm working on has a legacy code base in Java already. One of the Java annoyances that has plagued my work with in the past was the amount code required to work with regular expressions. I go back a long way with regular expressions, Perl (a good friend, long ago) supports it natively and the code I've written in recent years, mostly Python and Ruby, benefitted from the regular expression support in those languages.
I've been using Scala for the past several weeks, so far it's been a win. My use of Scala to date has been as a "better Java." I'm peeling the onion layers of functional programming and Scala's APIs, gradually improving the code with richer Scala constructs. But in the meantime, I'm mostly employing plain old imperative programming. At this point, I think that's the best way to learn it. Trying to dive into the functional programming deep end can be a bit of a struggle. If you don't know Java, that may not mean much but for myself, I'd used Java extensively in years past and the project that I'm working on has a legacy code base in Java already. One of the Java annoyances that has plagued my work with in the past was the amount code required to work with regular expressions. I go back a long way with regular expressions, Perl (a good friend, long ago) supports it natively and the code I've written in recent years, mostly Python and Ruby, benefitted from the regular expression support in those languages.
By annoyance, let's take an example that's simple in Perl since regexps are most succint in the language of the camel (and historically the state of Perl is given in a State of the Onion speech):
#!/usr/bin/env perl # re.pl $input = "camelCaseShouldBeUnderBar"; $input=~ s/([a-z])([A-Z])/$1 . "_" . lc($2)/ge; print "$input\n"; # outputs: camel_case_should_be_under_bar # now go the other way $input = "under_bar_should_be_camel_case"; $input=~ s/([a-z])_([a-z])/$1 . uc($2)/ge; print "$input\n"; # outputs underBarShouldCamelCaseWanna do the same thing in Java? Well, for simple stuff Java's Matcher has a replaceAll method that is, well, dumb as a door knob. If you want the replacement to be based on characters captured from the input and processed in some way, you'd pretty much have to do something like this:
import java.util.regex.Pattern;
import java.util.regex.Matcher;
public class Re {
Pattern underBarPattern;
Pattern camelCasePattern;
public Re() {
underBarPattern = Pattern.compile("([a-z])_([a-z])");
camelCasePattern = Pattern.compile("([a-z])([A-Z])");
}
public String camel(String input) {
StringBuffer result = new StringBuffer();
Matcher m = underBarPattern.matcher(input);
while (m.find()) {
m.appendReplacement(result, m.group(1) + m.group(2).toUpperCase());
}
m.appendTail(result);
return result.toString();
}
public String underBar(String input) {
StringBuffer result = new StringBuffer();
Matcher m = camelCasePattern.matcher(input);
while (m.find()) {
m.appendReplacement(result, m.group(1) + "_" + m.group(2).toLowerCase());
}
m.appendTail(result);
return result.toString();
}
public static void main(String[] args) throws Exception {
Re re = new Re();
System.out.println("camelCaseShouldBeUnderBar => " + re.underBar("camelCaseShouldBeUnderBar"));
System.out.println("under_bar_should_be_camel_case => " + re.camel("under_bar_should_be_camel_case"));
}
}
OK, that's way too much code. The reason why this is such a PITA in Java is that the replacement part can't be an anonymous function, or a function at all, due to the fact that... Java doesn't have them. Perhaps that'll change in Java 7. But it's not here today.
Anonymous functions (in the camel-speak of olde, we might've said "coderef") is one area where Scala is just plain better than Java. scala.util.matching.Regex has a replaceAllIn method that takes one as it's second argument. Furthermore, you can name the captured matches in the constructor. The anonymous function passed in can do stuff with the Match object passed in. So here's my Scala equivalent:
import scala.util.matching.Regex
val re = new Regex("([a-z])([A-Z])", "lc", "uc")
var output = re.replaceAllIn("camelCaseShouldBeUnderBar", m =>
m.group("lc") + "_" + m.group("uc").toLowerCase)
println(output)
val re = new Regex("([a-z])_([a-z])", "first", "second")
output = re.replaceAllIn("under_bar_should_be_camel_case", m =>
m.group("first") + m.group("second").toUpperCase)
println(output)
In both cases, we associate names to the capture groups in the Regex constructor. When the input matches, the resulting Match object makes the match data available to work on. In the first case
m.group("lc") + "_" + m.group("uc").toLowerCase
and in the second
m.group("first") + m.group("second").toUpperCase)
That's fairly succinct and certainly so much better than Java. By the way, if regular expressions are a mystery to you, get the Mastering Regular Expressions book. In the meantime, keep peeling the onion.
( Aug 29 2010, 06:40:32 PM PDT ) Permalink
Saturday July 24, 2010
Getting Started with a Scala 2.8 Toolchain
![]() With the release of version 2.8 and enthusiasm amongst my current project's collaborators, I've fired up my latent interest in scala. There's a lot to like about scala: function and object orientation, message based concurrency and JVM garbage collection, JITing, etc; it's a really interesting language. The initial creature comforts I've been looking for are a development, build and test environment I can be productive in. At present, it looks like the best tools for me to get rolling are IntelliJ, sbt and ScalaTest. In this post, I'll recount the setup I've arrived at on a MacBook Pro (Snow Leopard), so far so good.
With the release of version 2.8 and enthusiasm amongst my current project's collaborators, I've fired up my latent interest in scala. There's a lot to like about scala: function and object orientation, message based concurrency and JVM garbage collection, JITing, etc; it's a really interesting language. The initial creature comforts I've been looking for are a development, build and test environment I can be productive in. At present, it looks like the best tools for me to get rolling are IntelliJ, sbt and ScalaTest. In this post, I'll recount the setup I've arrived at on a MacBook Pro (Snow Leopard), so far so good.
Development:
I've used Eclipse for years and there's a lot I like about it but I've also had stability problems, particularly as plugins are added/removed from the installation (stay away from the Aptana ruby plugin, every attempt to use it results in an unstable Eclipse for me). So I got a new version of IntelliJ ("Community Edition"); the Scala plugin for v2.8 doesn't work with the IntelliJ v9.0.2 release so the next task was to grab and install a pre-release of v9.0.3 (see ideaIC-95.413.dmg). I downloaded recent build of the scala plugin (see scala-intellij-bin-0.3.1866.zip) and unzipped it in IntelliJ's plugins directory (in my case, "/Applications/IntelliJ IDEA 9.0.3 CE.app/plugins/"). I launched IntelliJ, Scala v2.8 support was enabled.
Build:
I've had love/hate relationships in the past with ant and maven; there's a lot to love for flexibility with the former and consistency with the latter (hat tip at "convention over configuration"). There's a lot to hate with the tedious XML maintenance that comes with both. So this go around, I'm kicking the tires on simple build tool. One of the really nice bits about sbt is that it has a shell you can run build commands in; instead of waiting for the (slow) JVM launch time everytime you build/test you can incur the launch penalty once to launch the shell and re-run those tasks from within the sbt shell. Once sbt is setup, a project can be started from the console like this:
$ sbt update
You'll go into a dialog like this:
Project does not exist, create new project? (y/N/s) y Name: scratch Organization: ohai Version [1.0]: 0.1 Scala version [2.7.7]: 2.8.0 sbt version [0.7.4]:Now I want sbt to not only bootstrap the build system but also bootstrap the IntelliJ project. There's an sbt plugin for that. Ironically, bringing up the develop project requires creating folder structures and code artifacts... which is what your development environment should be helping you with. While we're in there, we'll declare our dependency on the test framework we want (why ScalaTest isn't in the scala stdlib is mysterious to me; c'mon scala, it's 2010, python and ruby have both shipped with test support for years). So, fallback to console commands and vi (I don't do emacs) or lean on Textmate.
$
mkdir project/build$
vi project/build/Project.scala
import sbt._
class Project(info: ProjectInfo) extends DefaultProject(info) with IdeaProject {
// v1.2 is the current version compatible with scala 2.8
// see http://www.scalatest.org/download
val scalatest = "org.scalatest" % "scalatest" % "1.2" % "test->default"
}
$ mkdir -p project/plugins/src$
vi project/plugins/src/Plugins.scala
import sbt._
class Plugins(info: ProjectInfo) extends PluginDefinition(info) {
val repo = "GH-pages repo" at "http://mpeltonen.github.com/maven/"
val idea = "com.github.mpeltonen" % "sbt-idea-plugin" % "0.1-SNAPSHOT"
}
$ sbt update$
sbt ideaBack in IntelliJ, do "File" > "New Module" > select "Import existing module" and specify the path to the "scratch.iml" file that that last console command produced.
Note how we declared our dependency on the test library and the repository to get it from with two lines of code, not the several lines of XML that would be used for each in maven.
Test:
Back in IntelliJ, right click on src/main/scala and select "New" > "Package" and specify "ohai.scratch". Right click on that package and select "New" > "Scala Class", we'll create a class ohai.scratch.Bicycle - in the editor put something like
package ohai.scratch
class Bicycle {
var turns = 0
def pedal { turns +=1 }
}
Now to test our bicycle, do similar package and class creation steps in the src/test/scala folder to create ohai.scratch.test.BicycleTest:
package ohai.scratch.test
import org.scalatest.Spec
import ohai.scratch.Bicycle
class BicycleSpec extends Spec {
describe("A bicycle, prior to any pedaling -") {
val bike = new Bicycle()
it("pedal should not have turned") {
expect(0) { bike.turns }
}
}
describe("A bicycle") {
val bike = new Bicycle()
bike.pedal
it("after pedaling once, it should have one turn") {
expect(1) { bike.turns }
}
}
}
Back at your console, go into the sbt shell by typing "sbt" again. In the sbt shell, type "test". In the editor, make your bicycle do more things, write tests for those things (or reverse the order, TDD style) and type "test" again in the sbt shell. Lather, rinse, repeat, have fun.
( Jul 24 2010, 11:51:30 AM PDT ) Permalink
Comments [4]
Thursday September 10, 2009
Hub-a-dub-bub, feed clouds in a tub
 While at Technorati, I observed a distinct shift around summer of 2005 in the flow of pings from largely worthwhile pings to increasingly worthless ones. A ping is a simple message with a URL. Invented by Dave Winer, it was originally implemented with XML-RPC but RESTful variants also emerged. The intention of the message is "this URL updated." For a blog, the URL is the main page of the blog; it's not the feed URL, a post URL ("permalink") or any other resource on the site - it's just the main page. Immediately, that narrow scope has a problem; as a service that should do something with the ping, the notification has no more information about what changed on the site. A new post? Multiple new posts? Um, what are the new post URL(s)? Did the blogroll change? And so on. Content fetching and analysis is cheap; network latencies, parsing content and doing interesting stuff with it is easy at low volumes but is difficult to scale.
While at Technorati, I observed a distinct shift around summer of 2005 in the flow of pings from largely worthwhile pings to increasingly worthless ones. A ping is a simple message with a URL. Invented by Dave Winer, it was originally implemented with XML-RPC but RESTful variants also emerged. The intention of the message is "this URL updated." For a blog, the URL is the main page of the blog; it's not the feed URL, a post URL ("permalink") or any other resource on the site - it's just the main page. Immediately, that narrow scope has a problem; as a service that should do something with the ping, the notification has no more information about what changed on the site. A new post? Multiple new posts? Um, what are the new post URL(s)? Did the blogroll change? And so on. Content fetching and analysis is cheap; network latencies, parsing content and doing interesting stuff with it is easy at low volumes but is difficult to scale.
In essence, a ping is a cheap message to prompt an expensive analysis to detect change. It's an imbalanced market of costs and benefits. Furthermore, even if the ping had a richer payload of information, pings lack another very important component: authenticity. These cheap messages can be produced by anybody for any URL and the net result I observed was that lots of people produced pings for lots of things, most of which weren't representative of real blogs (other types of sites or just spam) or real changes on blogs, just worthless events that were resource intensive to operate on. When I left Technorati in March (2009), we were getting around 10 million pings a day, roughly 95% of them of no value. Pings are the SMTP of the blogosphere; weak identity systems, spammy and difficult to manage at scale.
Besides passively waiting for pings, the other method to find things that have changed is to poll sites. But polling is terribly inefficient. To address those inefficiencies, FriendFeed implemented Simple Update Protocol. SUP is reminiscent of another Dave Winer invention, changes.xml however SUP accounts for discovery and offers a more compact format.
But SUP wasn't the first effort to address the aforementioned deficiencies, 2005 saw a lot of activity around something called "feedmesh." Unfortunately, the activity degenerated into a lot of babble; noise I attribute to unclear objectives and ego battles but I'm sure others have their own interpretation. The feedmesh discussion petered out and little value beyond ping-o-matic and other ping relayers emerged from it. Shortly thereafter SixApart created their atom stream, I think spearheaded by Brad Fitzpatrick. The atom stream is essentially a long lived HTTP connection that streams atom elements to the client. The content flow was limited to SixApart's hosted publishing platforms (TypePad, LiveJournal and Vox) and the reliability wasn't that great, at least in the early days, but it was a big step in the right direction for the blog ecosystem. The atom stream was by far the most efficient way to propogate content from the publishing platform to interested parties such as Technorati operating search, aggregation and analytic systems. It eliminates the heavyweight chatter of cheap ping messages and the heavyweight process that follows: fetch page, discover feed, fetch feed, inspect contents and do stuff with it.
So here we are in 2009 and it feels like deja-vu all over again. This time Dave is promoting rssCloud. rssCloud does a waltz of change notification; the publisher notifies a hub, the hub broadcasts notifications to event subscribers and the subscriber does the same old content fetch and analysis cycle above. rssCloud seems fundamentally flawed in that it is dependent on IP addresses as identifiers. Notification receivers who must use new a IP address must re-subscribe. I'm not sure how an aggregator should distribute notificaton handling load across a pool of IP addresses. The assumption is that notification receivers will have stable, singular IP addresses; rssCloud appears scale limited and a support burden. The focus on specification simplicity has its merits, I think we all hate gratuitous complexity (observe the success of JSON over SOAP). However, Dave doesn't regard system operations as an important concern; he'll readily evangelize a message format and protocol but the real world operability is Other Peoples Problem.
Pubsubhubub (hey, Brad again) has a similar waltz but eliminates the content fetch and analysis cycle ergo it's fundamentally more efficient than rssCloud's waltz. Roughly, Pubsubhubub is to the SixApart atom stream what rssCloud is to old school XML-RPC ping. If I were still at Technorati (or working on event clients like Seesmic, Tweetdeck, etc), I would be implementing Pubsubhubbub and taking a pass on rssCloud. With both systems, I'd be concerned with a few issues. How can the authenticity of the event be trusted? Yes, we all like simplicity but looking at SMTP is apt; now mail systems must be aware of SPF, DKIM, SIDF, blahty blah blah. Its common for mail clients to access MTA's over cryptographically secure connections. Mail is a mess but it works, albeit with a bunch of junk overlaid. I guess this is why Wave Protocol has gathered interest. Anyway, Pubsubhubbub has a handshake during the subscription processes, though that looks like a malicious party could still spin up endpoints with bogus POSTs. I'd like to see an OAuth or digest authentication layer in the ecosystem. Yea, it's a little more complicated, but nothing onerous... suck it up. Whatever. Brad knows the authenticity rap, I mean he also invented OpenID (BTW, we adopted OpenID at Technorati back in 2007). At Technorati we had to implement ping throttling to combat extraneous ping bots; either daemons or cron jobs that just ping continuously, whether the URL has changed or not. You can't just blacklist that URL, we don't know it was the author generating those pings, there's no identity authenticity there. We resorted to blocking IP addresses but that scales poorly and creates other support problems. We had 1000's of domain names blocked and whole class C networks blocked but it was always a wackamole exercise; so much for an open blogosphere, a whitelist is the only thing that scales within those constraints. Meanwhile, back to rssCloud and Pubsubhubbub, what event delivery guarantees can be made? If a data center issue or something else interrupts event flow, are events spooled so that event consumption can be caught up? How can subscribers track the authenticity of the event originators? How can publishers keep track of who their subscribers are? Well, I'm not at Technorati anymore so I'm no longer losing any sleep over these kinds of concerns but do I care about the ecosystem. For more, Matt Mastracci is posting interesting stuff about Pubsubhubbub and a sound comparison was posted to Techcrunch yesterday.
( Sep 10 2009, 12:35:37 PM PDT ) Permalink
Sunday August 02, 2009
Business Models in Consulting, Contracting and Training Since leaving Technorati last spring, I've been working independently with a few entrepreneurs on their technical platforms. This has mostly entailed working with tools around Infrastructure-As-A-Service (AWS), configuration management (Chef and RightScale), search (Solr) and learning a lot about programming and going into production with ruby and rails. I've spoken to a number of friends and acquaintances who are working as consultants, contractors, technical authors and trainers. Some are working as lone-wolves and others working within or have founded larger organizations. I'm always sniffing for where the upside opportunities are and the question that comes to my mind is: how do such businesses scale?
A number of technology services companies that I've taken notice of have been funded in the last year or so including OpsCode, Reductive Labs, Cloudera and Lucid Imagination. I think all of these guys are in great positions; virtual infrastructure (which is peanut butter to the chocolate of IaaS), big data and information retrieval technologies provide the primordial goo that will support new mobile, real time and social software applications. They are all working in rapid innovation spaces that hold high value potentials but also new learning and implementation challenges that rarefy specialized knowledge.
Years ago when I was working with Covalent Technologies, we tried to build a business around "enterprise open source" with Apache, Tomcat, etc as the basis. Packaging and selling free software is difficult. On the one hand, offering a proven technology stack configuration to overcome the usual integration and deployment challenges as well as providing a support resource is really valuable to Fortune 500's and such. However, my experience there and observations of what's happened with similar businesses (such as Linuxcare and SpikeSource) has left me skeptical how big the opportunity is. After all, while you're competing with the closed-source proprietary software vendors, you're also competing with Free.
The trend I'm noticing is the branching out away from the packaging and phone support and into curriculum. Considering that most institutional software technology education, CS degrees, extended programs, etc have curricula that are perpetually behind the times, it makes sense that the people who possess specialized knowledge on the bleeding edge lead the educational charge. Lucid Imagination, Cloudera and Scale Unlimited are illustrating this point. While on-premise training can be lucrative, I think online courseware may provide a good answer to the business scale question.
For myself, I'm working with and acquiring knowledge in these areas tactically. Whatever my next startup will be, it should be world-changing and lucrative. And I'll likely be using all of these technologies. Thank goodness these guys are training the workforce of tomorrow!
startups scalability entrepreneuring
( Aug 02 2009, 08:57:08 PM PDT ) Permalink
Thursday May 21, 2009
Configuring Web Clouds with Chef
![]() I'm not generally passionate about network and system operations, I prefer to focus my attention and creativity on system and software architectures. However, infrastructure provisioning, application deployment, monitoring and maintenance are facts of life for online services. When those basic functions aren't functioning well, then I get passionate about them. When service continuity is impacted and operations staff are overworked, it really bothers me; it tells me that I or other developers I'm working with are doing a poor job of delivering resilient software. I've had many conversations with folks who've accepted as a given that development teams and operations teams have friction between them; some even suggest that they should. After all, so goes that line of thinking, the developers are graded on how rapidly they implement features and fix bugs whereas the operators are graded on service availability and performance. Well, you can sell that all you want but I won't buy it.
I'm not generally passionate about network and system operations, I prefer to focus my attention and creativity on system and software architectures. However, infrastructure provisioning, application deployment, monitoring and maintenance are facts of life for online services. When those basic functions aren't functioning well, then I get passionate about them. When service continuity is impacted and operations staff are overworked, it really bothers me; it tells me that I or other developers I'm working with are doing a poor job of delivering resilient software. I've had many conversations with folks who've accepted as a given that development teams and operations teams have friction between them; some even suggest that they should. After all, so goes that line of thinking, the developers are graded on how rapidly they implement features and fix bugs whereas the operators are graded on service availability and performance. Well, you can sell that all you want but I won't buy it.
In my view, developers need to deliver software that can be operated smoothly and operators need to provide feedback on how smoothly the software is operating; dev and ops must collaborate. I accept as a given that developers
- Use source control
- Write unit tests (after the fact or before/during TDD style)
- Write functional and integration tests
- Maintain a build system for running test harnesses and packaging code
- Document internal architecture and operating interfaces
- Plan for change with respect to scale charactistics and functionality
- Use configuration management
- Automate infrastructure provisioning, code deployment and rollback
- Monitor infrastructure and application metrics
So I've been giving Chef a test-drive for this infrastructure-on-EC2 management project that's been cooking. The system implemented the following use cases:
- Launch web app servers on EC2 with Apache, Passenger, RoR (+other gems) and overlay a set of rails apps out of git
- Launch a pair of reverse proxies (with ha-proxy) in front of the app servers - and reconfigure them when the set of app servers is expanded or contracted
- Configure the proxy for failover with heartbeat
- Add new rails apps to the set of app servers
- Updating/rolling back rails apps
There's a lot of energy in the Chef community (check out Casserole), combined with monitoring, log management and cloud technologies, I think there's a lot of IT streamlining ahead. Perhaps the old days of labor and communication intensive operations will give way to a new era of autonomic computing. I'll post further about some of the mechanics of working with ruby, rails, chef, EC2, chef-deploy and other tools in the weeks ahead (particularly now that EC2 has native load balancing, monitoring and auto-scaling capabilities). I'll also talk a bit about this stuff at a Velocity BoF. If you're thinking about attending Velocity, O'Reilly is offering 30% off to the first 30 people to register today with the code vel09d30 today (no I'm not getting any kinduva kickback from O'Reilly). And you can catch Infrastructure in the Cloud Era with Adam Jacob (Opscode), Ezra Zygmuntowicz (EngineYard) to learn more about Chef and cloud management.
chef puppet cfengine ec2 aws ruby cloud computing velocity
( May 21 2009, 12:30:07 PM PDT ) PermalinkComments [2]
Tuesday March 31, 2009
Cloning VMware Machines
![]() I bought a copy of VMware Fusion on special from Smith Micro (icing on the cake: they had a 40% off special that week) specifically so I could simulate a network of machines on my local MacBook Pro. While I've heard good things about Virtual Box, one of the other key capabilities I was looking for from MacIntosh virtualization software was the ability convert an existing Windows installation to a virtual machine. VMware reportedly has the best tools for that kind of thing. I have an aging Dell with an old XP that I'd like to preserve when I finally decide to get rid of the hardware; when it's time to Macify, I'll be good to go.
I bought a copy of VMware Fusion on special from Smith Micro (icing on the cake: they had a 40% off special that week) specifically so I could simulate a network of machines on my local MacBook Pro. While I've heard good things about Virtual Box, one of the other key capabilities I was looking for from MacIntosh virtualization software was the ability convert an existing Windows installation to a virtual machine. VMware reportedly has the best tools for that kind of thing. I have an aging Dell with an old XP that I'd like to preserve when I finally decide to get rid of the hardware; when it's time to Macify, I'll be good to go.
I started building my virtual network very simply, by creating a CentOS VM. Once I had my first VM running, I figured I could just grow the network from there; I was expecting to find a "clone" item in the Fusion menus but alas, no joy. So, it's time to hack. Looking around at the artifacts that Fusion created, a bunch of files in a directory named for the VM, I started off by copying the directory, the files it contained that had the virtual machine name as components of the file name and edited the metadata files ({vm name}.vmdk/.vmx/.vmxf). Telling Fusion to launch that machine, it prompted if this was a copy or a moved VM - I told it that it was copied and the launch continued. Both launched VM's could ping each other so voila: my virtual network came into existence.
I've since found another procedure to create "linked clones" in VMware Fusion. It looks like this will be really useful for my next scenario of having two different flavors of VM's running on my virtual network. The setup I want to get to is one where I can have "manager" host (to run provisioning, monitoring and other management applications) and cookie-cutter "worker" hosts (webservers, databases, etc). Ultimately, this setup will help me tool up for cloud platform operations; I have more Evil Plans there.
So all of this has me wondering: why doesn't VMware support this natively? Where's that menu option I was looking for? Is there an alternative to this hackery that I just overlooked?
vmware virtualization centos vmware fusion vm cloning
( Mar 31 2009, 09:12:22 AM PDT ) PermalinkComments [2]
Tuesday March 10, 2009
More Changes At Technorati (this time, it's personal)
![]() My post last week focused on some of the technology changes that I've been spearheading at Technorati but this time, I have a personal change to discuss. When I joined Technorati in 2004, the old world of the web was in shambles. The 1990's banner-ads-on-a-CPM-basis businesses were collapsed. The editorial teams using big workflow-oriented content management system (CMS) infrastructure (which I worked on in the 90's) were increasingly eclipsed by the ecosystem of blogs. Web 2.0 wasn't yet the word on everyone's lips. But five years ago, Dave Sifry's infectious vision for providing "connective tissue" for the blog ecosystem, tapping the attention signals and creating an emergent distributed meta-CMS helped put it there. Being of service to bloggers just sounded too good, so I jumped aboard.
My post last week focused on some of the technology changes that I've been spearheading at Technorati but this time, I have a personal change to discuss. When I joined Technorati in 2004, the old world of the web was in shambles. The 1990's banner-ads-on-a-CPM-basis businesses were collapsed. The editorial teams using big workflow-oriented content management system (CMS) infrastructure (which I worked on in the 90's) were increasingly eclipsed by the ecosystem of blogs. Web 2.0 wasn't yet the word on everyone's lips. But five years ago, Dave Sifry's infectious vision for providing "connective tissue" for the blog ecosystem, tapping the attention signals and creating an emergent distributed meta-CMS helped put it there. Being of service to bloggers just sounded too good, so I jumped aboard.
Through many iterations of blogospheric expansion, building data flow, search and discovery applications, dealing with data center outages (and migrations) and other adventures, it's been a long strange trip. I've made a lot of fantastic friends, contributed a lot of insight and determination and learned a great deal along the way. I am incredibly proud of what we've built over the last five years. However today it's time for me to move on, my last day at Technorati will be next week.
Technorati has a lot of great people, technology and possibilities. The aforementioned crawler rollout provides the technology platform with a better foundation that I'm sure Dorion and the rest of the team will build great things on. The ad platform will create an abundance of valuable opportunities for bloggers and other social media. I know from past experiences what a successful media business looks like and under Richard Jalichandra's leadership, I see all of the right things happening. The ad platform will leverage Technorati's social media data assets with the publisher and advertiser tools that will make Technorati an ad delivery powerhouse. I'm going to remain a friend of the company's and do what I can to help its continued success, but I will be doing so from elsewhere.
I want to take a moment to thank all of my colleagues, past and present, who have worked with me to get Technorati this far. The brainstorms, the hard work, the arguments and the epiphanies have been tremendously valuable to me. Thank You!
I'm not sure what's next for me. I feel strongly that the changes afoot in cloud infrastructure, open source data analytics, real time data stream technologies, location based services (specifically, GPS ubiquity) and improved mobile devices are going to build on Web 2.0. These social and technology shifts will provide primordial goo out of which new innovations will spring. And I intend to build some of them, so brace yourself for Web 3.0. It's times like these when the economy is athrash that the best opportunities emerge and running for cover isn't my style. The next few years will see incumbent players in inefficient markets crumble and more powerful paradigms take their place. I'm bringing my hammer.
( Mar 10 2009, 02:06:20 PM PDT ) PermalinkComments [4]
Wednesday March 04, 2009
Welcome to the Technorati Top 100, Mr. President
 Since its inception just 6 weeks ago, the White House Blog has had a tremendous center of gravity. I noted the volume of links coming in to the White House Blog after the first week. This is an existential moment for the blogosphere because today the White House Blog has 3216 links from 2323 blogs. And so it's official: the White House Blog has reached the Technorati Top 100.
Since its inception just 6 weeks ago, the White House Blog has had a tremendous center of gravity. I noted the volume of links coming in to the White House Blog after the first week. This is an existential moment for the blogosphere because today the White House Blog has 3216 links from 2323 blogs. And so it's official: the White House Blog has reached the Technorati Top 100.
I find myself reflecting on what the top 100 looked like four years ago, after the prior presidential inauguration, and what it looks like today; the blogosphere is a very different place. Further down memory lane, who recalls when Dave Winer and Instapundit were among the top blogs? Yep, most of the small publishers have been displaced by those with big businesses behind them. Well, at least BoingBoing endures but Huffpo and Gizmo better watch out, here comes Prezbo.
technorati white house inauguration blog
( Mar 04 2009, 10:59:16 PM PST ) PermalinkNew Crawlers At Technorati
 A lot of changes are afoot at Technorati. Over the last year or so, we've been looking inward at the infrastructure and asking ourselves, "How can we do this better?". The data spigot that Technorati builds on was the first thing to focus on, it's a critical part in one leg of the back-end infrastructure tripod. The tripod consists of data acquisition, search and analytics Technorati; while the ping handling and queuing are relatively simple affairs the crawler is the most sophisticated of the data acquisition subsystems. It's proper functioning is critical to the functioning of the other legs; when it doesn't function well, search and analytics don't either (GIGO="garbage in/garbage out").
A lot of changes are afoot at Technorati. Over the last year or so, we've been looking inward at the infrastructure and asking ourselves, "How can we do this better?". The data spigot that Technorati builds on was the first thing to focus on, it's a critical part in one leg of the back-end infrastructure tripod. The tripod consists of data acquisition, search and analytics Technorati; while the ping handling and queuing are relatively simple affairs the crawler is the most sophisticated of the data acquisition subsystems. It's proper functioning is critical to the functioning of the other legs; when it doesn't function well, search and analytics don't either (GIGO="garbage in/garbage out").
As Dorion mentioned recently, we're retiring the old crawler. Why are we giving the old crawler getting an engraved watch and showing it to the door? Well, old age is one reason. The original spider is a technology that dates back to 2003, the blogosphere has changed a lot since then and we have a much better developed understanding of the requirements. The original spider code has presented a sufficient number of GIGO-related and code maintenance challenges to warrant a complete re-thinking. It contrasts starkly with the replacement.
- Data model
- There are a lot of ways to derive structural information out of the pages and feeds that a blog presents. The old spider used event driven parses, building a complex state as it went with flat data structures (lists and hashes). The new one uses the composed web documents to populate a well-defined object model; all crawls normalize the semi-structured data found on the web to that model.
- Crawl persistence
- The old spider was hard-wired to persist the aforementioned data structure elements to relational databases (sharded MySQL instances) while it was parsing, so that the flow of saving parsed data was closely coupled with parsing events, forsaking transactional integrity and consuming costly resources. The new spider composes and saves its parse result as a big discreet object (not collections of little objects in an RDBMS). This reduced the hardware footprint by an order of magnitude.
- Operational visibility
- Whether a blog's page structure was understood (or not), the feed was well formed (or not) or any of the many other things that determine the success or quality of a blog's crawl was opaque under the old spider. With the new spider, detailed metadata and metrics are tracked during the crawl cycles. This better enables the team to support bloggers and extend the system's capabilities.
- Unit tests
- Wherever you have complex, critical software you want to have unit tests. The old spider had almost no unit tests and was developed in a way that made testing the things that mattered most exceptionally difficult. The new spider was developed with a test harness upfront, it now has hundreds of tests that validate thousands of aspects of the code. The test are uniformly invoked by the developers and automatically whenever the code is updated (AKA under continuous integration).
Another change that we've made is to the legacy assumption that everything that pings is a blog. That assumption proved to be increasingly untenable as the ping meme spread amongst those who didn't really understand the difference between some random page and a blog, nefarious publishers (spammers) and other perpetrators of spings. Over 90% of the pings hitting Technorati are rejected outright because they've been identified as invalid pings. A large portion of the remainder are later determined to be invalid but we now have a rigorous system in place for filtering out the noise. We've reduced the spam level considerably (as mentioned in a prior post). For instance, there's a whole genre of splogs that are pornography focused (hardcore pictures, paid affiliate links, etc) that previously plagued our data; now we've eliminated a lot of that nonsense from the index.
Here are a pair of charts showing the daily occurrence of a particular porn term in the index.
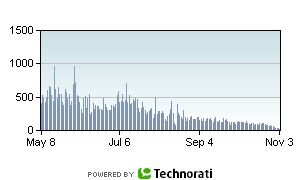
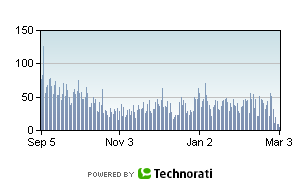
As you can see, that's an order of magnitude reduction; 90% of the occurrences of that term was spam.
So what's next for the crawler? We've got some stragglers on the old spider, we're going to migrate them over in the next few days. There are still a lot of issues to shake out, as with any new software (for instance, there are still some error recovery scenarios to deal with). But it's getting better all of the time (love that song). We'll be rolling out new tools internally for identifying where improvements are needed, ultimately we'd like to enable bloggers to help themselves to publish, get crawled, be found and recognized more effectively. And there are more changes afoot, stay tuned.
technorati web crawling software spam splogs
( Mar 04 2009, 08:31:16 PM PST ) PermalinkComments [2]
Friday February 27, 2009
Code Is Social
 Like many software developers, I confess that I have found myself on occasion coming back to old code that I wrote asking, "What was I thinking?" Where it's my code, this WWIT question doesn't happen very often these days but in general I can't count the number of times I've encountered and had to work on code that was not written to be read. I think sometimes programmers write terse code and regard its brevity as a badge of honor, "If I'm wizardly enough to write this, then only True Wizards will read it." Or maybe it's just laziness or hurriedness, these code mysteries are akin to omitting comments, API documentation and other communication artifacts. When I see non-descriptive variable names, gratuitous indirection, excessive right indenting, monkey patching or unnecessary cyclomatic complexity, it's almost anti-social behavior; it's a communication fail more than a functional one. Likewise, gratuitous verbosity stifles communication in the opposite manner; this isn't pre-school - grasp of the ABC's is assumed. So spelling out what code is doing in this belabored fashion is just silly:
Like many software developers, I confess that I have found myself on occasion coming back to old code that I wrote asking, "What was I thinking?" Where it's my code, this WWIT question doesn't happen very often these days but in general I can't count the number of times I've encountered and had to work on code that was not written to be read. I think sometimes programmers write terse code and regard its brevity as a badge of honor, "If I'm wizardly enough to write this, then only True Wizards will read it." Or maybe it's just laziness or hurriedness, these code mysteries are akin to omitting comments, API documentation and other communication artifacts. When I see non-descriptive variable names, gratuitous indirection, excessive right indenting, monkey patching or unnecessary cyclomatic complexity, it's almost anti-social behavior; it's a communication fail more than a functional one. Likewise, gratuitous verbosity stifles communication in the opposite manner; this isn't pre-school - grasp of the ABC's is assumed. So spelling out what code is doing in this belabored fashion is just silly:
# an array to collect permalinks
permalinks = []
# loop over the feed entries
for entry in feed.entries:
permalinks.append(entry.link)
Whereas this is clear
# extract an array of permalinks from the feed entries permalinks = [ entry.link for entry in feed.entries ]OK, I'm assuming the reader knows what a Python list comprehension does. The first one is using a lot of vertical space to satisfy a very simple intent. I often find the opposite problem, excessive brevity, is authored by those enamored with their language's idioms. Software written with scripting languages often exhibit this; Perl is famous for expressiveness (I say this lovingly as a repentant x-Perl Wizard) but even the languages with adherents claiming their tongue is more "readable" have those same users donning wizard hats, trying to be clever. Ever tried to maintain Python code riddled with nested list comprehensions containing lambdas? Ruby, similar idiomatic norms abound, 'nuf said.
I've appreciated celebrations of wizardry (see A folding language) but there's more to wizardry than meta-programming and brevity. Coding like a wizard doesn't mean being so clever that only other wizards can collaborate. In my view, a true wizard has the wisdom to steer clear of verbose indulgences and terse spells; the wizard walks the middle path of clarity so that the code is not dumbed-down but the apprentice will grasp the intent. The wizard's code should read as poetry.
When code is unsocial (or anti-social), the quality suffers. Complex software needs a gene pool - lots of eyeballs, lots of variant perspectives and experiences. A small gene pool leads to in-bred ideas. Thus code from a lone wolf (even a kick-ass wolf) will usually be of lower quality than code developed by a plurality (unless its a plurality of novices, then all bets are off).
My plea to fellow crafters of bits: please code for clarity. Don't be so brief that your intentions are unclear. And don't be so garrulous that your intention is lost in the verbiage. Again, I'm not claiming innocence of these sins of code. But over the years I've become considerably more aware of the costs and benefits in the choices between brevity and verbosity. Perhaps clarity is in the eye of beholder or perhaps more narrowly, in the eye of the author. But I try to look at my own code objectively and ask, "If I don't see this code for six months and then come back to it to do some maintenance, will today's intent be clear?" I hope the code I write will be approachable by those who come behind me to work on it, especially if it's me lest I ask myself the WWIT question.
Sigh, I'm venting because I just got side tracked refactoring some program code (and its single test) that lacked clarity. Thanks for indulging me this far. I'm gonna go listen to some old Social Distortion now, have a great weekend!
programming wizardry perl python ruby
( Feb 27 2009, 06:26:15 PM PST ) PermalinkComments [1]
Tuesday January 27, 2009
Inbloguration: One Week Later
![]() As mentioned last week on the Technorati blog, Technorati was crawling the new White House blog within a day of its launch. Most of the blogosphere doesn't require individual customization in our crawling framework but in some special cases, it must be done. The White House blog is a prime example of why this is so but I'm pleased to report that Technorati's new crawling technology makes what was impossible with our old crawler easy with the new one.
As mentioned last week on the Technorati blog, Technorati was crawling the new White House blog within a day of its launch. Most of the blogosphere doesn't require individual customization in our crawling framework but in some special cases, it must be done. The White House blog is a prime example of why this is so but I'm pleased to report that Technorati's new crawling technology makes what was impossible with our old crawler easy with the new one.
Given the volume of moderation that'd be required, it doesn't surprise me that the posts don't take comments. But there are other more basic blogging practices of concern:
- It doesn't have clear feed discovery. There are multiple
rel="alternate"elements in theheadsection of the HTML document. - The permalinks are irregular; the first few were under the blog URL, the rest have been under other paths on the whitehouse.gov site.
- The HTML doesn't have any of the common CSS attributes that indicate structural semantics; if I get to vote on this, I'll opt for hAtom
So how has the blog done in the last week? Well, it emerged in the top 1000 just five days after its inception. Keep an eye on the blog's Technorati blog info page - it's currently ranked 882 (1,876 links from 1440 blogs). Many of the links are to main blog page, citing its existence. But the majority of the links were to the kick-off post (date line reads: "Tuesday, January 20th, 2009 at 12:01 pm") and the inaugural address. Here are the posts and their link counts:
- Change has come to WhiteHouse.gov - 619 links from 552 blogs
- President Barack Obama's Inaugural Address - 217 links from 194 blogs
- A National Day of Renewal and Reconciliation - 146 links from 137 blogs
- President Obama delivers Your Weekly Address - 103 links from 97 blogs
- Statement released after the President rescinds "Mexico City Policy" - 34 links from 33 blogs
- Executive Orders to date - 27 links from 27 blogs
- The Whistle Stop Tour - 26 links from 24 blogs
- Honoring Dr. King's Legacy and Serving America - 22 links from 20 blogs
- From peril to progress - 17 links from 17 blogs
- Now Comes Lilly Ledbetter - 15 links from 13 blogs
- 58 years of Indian democracy - 4 links from 4 blogs
- The year of the ox - 3 links from 3 blogs
- Timothy Geithner sworn in as Secretary of the Treasury - 3 links from 3 blogs
- Press Briefing Highlights - 3 links from 3 blogs
- President Obama on the Selection of Kirsten Gillibrand - 2 links from 2 blogs
It's really encouraging to see the White House, specifically Macon Phillips, posting updates about President Obama's policies and political activities. Going forward, I hope to see more consistent publishing practices. For instance, should slug words be separated by underscores or hyphens? Should the proper names in URL slugs be mixed case (e.g. Timothy_Geithner_sworn_in) or down cased (e.g. now-comes-lilly-ledbetter)? It's less important which one but just pick one and stick to it! Also, the White House Blog should use durable URLs for permalinks: there's a posting with the path /blog_post/PressBriefingHighlights/, another with /president-obama-delivers-your-weekly-address - what are they going to use for the next post with highlights from a press briefing or next week's weekly address? If Mr. Phillips needs any further advise on effective blog publishing technology, I'm easy to find and happy to be of service.
whitehouse white house blog blogging blog+technology obama technorati inbloguration
( Jan 27 2009, 12:41:39 PM PST ) Permalink
Thursday December 25, 2008
Downturn, what downturn?
 Just the other day, Data Center Knowledge asked Are Colocation Prices Heading Higher? My immediate reaction was, that's a stupid question: last time VC funding went into hibernation, data center space was suddenly cheap and abundant. The article suggested that companies operating their own data centers will run to the colos as a cost cutting measure. Maybe, but I'm not so sure. Data center migrations can be expensive, risky operations. Methinks that the F500's inclined to undertake a migration would have done so already. The article cited a report emphasizing a shift from capital expenses to operating expenses.
Just the other day, Data Center Knowledge asked Are Colocation Prices Heading Higher? My immediate reaction was, that's a stupid question: last time VC funding went into hibernation, data center space was suddenly cheap and abundant. The article suggested that companies operating their own data centers will run to the colos as a cost cutting measure. Maybe, but I'm not so sure. Data center migrations can be expensive, risky operations. Methinks that the F500's inclined to undertake a migration would have done so already. The article cited a report emphasizing a shift from capital expenses to operating expenses.
Tier 1 says demand for data center space grew 14 percent over the past 12 months, while supply grew by just 6 percent, "exacerbating an already lopsided supply/demand curve."However, Tier 1 attributed the demand, "especially, (to) the primacy of the Internet as a vehicle for service and application delivery." With the litany of Techcrunch deadpool reports, I'm finding it difficult to believe that the data center space supply/demand will continue skewing.
Sure, it's not all bad news. Fred Wilson reports that Union Square Ventures will be Investing In Thick and Thin. Acknowledging that, "it is easier to invest in thin times. The difficult business climate starts to separate the wheat from the chaff and the strong companies are revealed." Wilson goes on to say
I don't feel that its possible, or wise, or prudent to attempt to time these (venture investment) cycles.Yes, the economy is gyrating in pain, but the four horsemen aren't galloping nearby. So take a pill, catch your breath and deal with it: the sun will come out, just don't bother trying to time it too carefully.
Our approach is to manage a modest amount of capital (in our case less than $300 million across two active funds) and deploy it at roughly $40 million per year, year in and year out no matter what part of the cycle we are in.
That way we'll be putting out money at the top of the market but also at the bottom of the market and also on the way up and the way down. The valuations we pay will average themselves out and this averaging allows us to invest in the underlying value creation process and not in the market per se.
Now, there's no shortage of reasons for gloom and doom: mega-ponzi schemes collapsing, banks and real estate combusting, the big 3 in various states of failure, yet BMW North America will raise list prices 0.7%. Before the complete credit breakdown, real estate volume was actually rising in a lot of places (ergo: prices were aligning supply and demand). I was at a William-Sonoma store in Albuquerque the other day, the place was mobbed. My point is that while the economy is retrenching (or the country is rebooting), the detritus will be separated (Wilson's wheat from chaff) and data center space should be cheap and abundant. Everything seems fine to me. At least until the next bubble.
For those of you observing that sort of thing, Merry Christmas!
colocation data centers economy
( Dec 25 2008, 01:20:14 PM PST ) Permalink
Monday December 15, 2008
World Leader Reflex Tests
 Will Chuck-The-Shoe-At-The-World-Leader be an Olympic sport in the years ahead? Since finishing with dinner this evening, I've found no less than three flash games and a compendium of animated GIF satires.
Will Chuck-The-Shoe-At-The-World-Leader be an Olympic sport in the years ahead? Since finishing with dinner this evening, I've found no less than three flash games and a compendium of animated GIF satires.
- Shoe Attack On President Already Turned Into A Crappy Flash Game (Kotaku)
- Sock and Awe
- The Bush Game
- Iraq Shoe Tosser Guy: The Animated Gifs (Boing Boing)



![[Valid RSS]](/images/valid-rss.png "Validate my RSS feed")