What's That Noise?! [Ian Kallen's Weblog]
 Sunday April 24, 2005
Sunday April 24, 2005
Thinking about Microformats and the Hi-Fi Web There is meaning to be derived from the web. But The Semantic Web has little to do with the web itself; it's more about creating parallel universes. The assumption that there must be a separate structure to identify meaning on the web is given by descriptions of The Semantic Web.
HTML has limited ability to classify the blocks of text on a page, apart from the roles they play in a typical document's organization and in the desired visual layout.OK, but those assumptions may be flawed. Yes, often markup is produced that only browsers "understand" to the extent that their responsibility is to render a visual layout. But it doesn't have to be that way.
For instance, right now, many web applications that display user profiles do so in a way that other applications can't understand. The data is flattened in a way that it can't be consumed and meaningfully reused. Perhaps the markup functions properly in web browsers; how the layout elements are identified and therefore stylable for proper display works. But if the markup can't be remarshalled into data, it's low-grade ore. The data becomes markup mojibake. The Semantic Websters say: RDF to the rescue! Just maintain a parallel universe of data! Sure, if the data is marked up in some random ad-hoc fashion without regard to the actual data relationships, it's a problem. Application developers seeking to mine that mis-HTML-ified data are forced to write custom parsers to grok that data. Usually, the remarshalling can't be done losslessly, it's a low-fidelity roundtrip.
Web applications typically do this:

Inside the markup, there is structure and embedded bits of meaning, microformats.
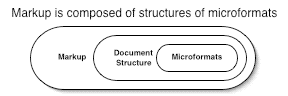
But the round trip is hard. Taking markup and deriving semantic meaning
from document elements usually requires understanding a lot about specific
implementations of data renderings.

The one-web is easy. The two-way web is hard.
When I talk about the one-way web, I'm not referring to protocols, HTTP methods or the "web two dot oh" read-write web. I'm referring to how code handles data to produce pages.
The microformats efforts aim to make the data on the web more understandable, more reusable and therefore more valuable without all of the complexities and problems that pervades The Semantic Web's RDF-centricity. By employing some basic XHTML norms, this data no longer needs to be flattened and lost. A microformat can be embedded in a web page's markup and be remarshalled as data. This is the high fidelity web.
The value of microformats is that your application could already be generating them and you're not even aware of it; there may be data that can be parsed, understood and reused waiting to have value unlocked. The microformat evangelism seeks to make your use of understandable markup intentional (disclaimer: I don't speak for Tantek but I speak with him frequently and I'm just purveying my current interpretation). Whereas microformats are about making the web natively understandable, The Semantic Web is about alternate formats.
When I've read others speak of microformats and alternate formats, I've seen discussion of RSS and Atom thrown in. By definition, these are not microformats, they are alternate formats. Not that there's anything wrong with the existing parallel universes, I just don't want to build more of them. How many goofy XSLT tricks does the world need to go from structured data with yet-another-vocabulary to renderable markup? The microformats answer is zero. Structured blogging looks like more markup mangling to get around, instead of fixing, the crappy user interface tiers of applications; it just doesn't seem necessary.
There's also a lot of interesting things that could be done to specify the intention of links. We'll have to call these nanoformats. They don't refer to data structures or relationships but they can still ascribe more meaning to links.
- Vote Links
- Attempts to indicate whether your reference to something is negative, positive or neutral. I have mixed feelings about this specifically, so I 'spose I should <a rel="vote-abstain"> abstain </a> from further commentary but in general, I like the idea of embellishing a link with intentions.
- nofollow
- Being able to distinguish between intentional links and accidental (i.e. placed not by the page author but some tool or untrusted third party) links is an important element of making the web more meaningful
I think the adoption of hCalendar, hCard (returning to the user profile case above) and the maturation of other microformats holds out the promise of the high fidelity web.
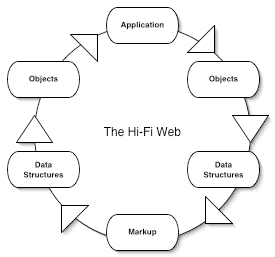
Internal application communications should, of course, do what is expeditious for development and runtime efficiency. But for the web (i.e. the the world wide one), the adoption of markup norms just makes sense. The diffusion of these formats means exercising patience while the web gets more coherent but I find it much more appealing to try solving the problem once in one rendering that the public can consume versus creating yet more parallel universes.
microformats microformat semanticweb web
( Apr 24 2005, 01:41:24 PM PDT ) Permalink


![[Valid RSS]](/images/valid-rss.png "Validate my RSS feed")