What's That Noise?! [Ian Kallen's Weblog]
 Sunday January 29, 2006
Sunday January 29, 2006
The Ironies of Blogger Off and on, I've been using a blog on blogger as a link blog and for other "quickies" to post. Tonight, I was closing some browser tabs with stuff I'd been reading about BerkeleyDB (JE) and went to post them here with ecto.
Strangely, ecto was giving me errors, so I check its console:
Response: Your post has been saved as a draft instead of published. You must go to Blogger.com to publish your post. To prevent these errors in the future, request a review at: http://www.blogger.com/unlock-blog.g?blogID=ABCDE Sorry for the inconvenienceBizarre! So, I go to the "unlock-blog" URL and get this:
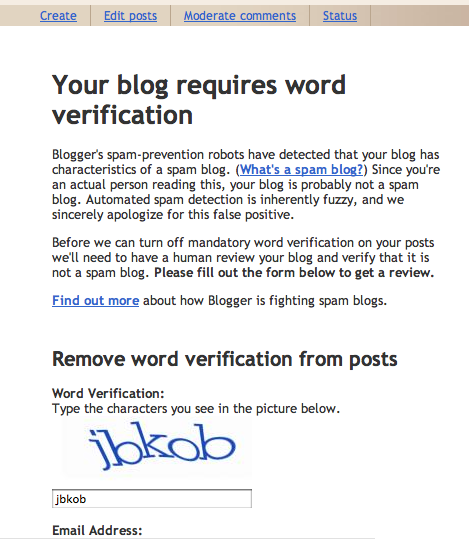
Inconvenience?! The links are to this page that outlines how feeble their anti-spam measures are. They don't have spam-prevention robots, who are they kidding? Will Robinson had a robot. Want to get me started on inconvenience?
The irony here is that it's relatively trivial to produce a list of recently created spam blogs from the blogspot service merely by watching the publish activities on any given day. I do it all of the time. There's a massive amount of spam on that service that percolates up from some simple correlations. And Technorati's index is subsequently scrubbed often on that account. It's a little inconvient. Yet the blogspot people continue to rely on the "Flag As Objectionable" button as their main weapon. Get a clue! Look how trivial to game that system is; I'll surmise that I got googlebowled (bloggerbowled would be more apt) by some dingleberry black hats. Very inconvenient. Given the rampant fraud going on within blogger, it doesn't take a rocket scientist to see.
Google is pretty much operating an open-relay, the blogosphere's equivalent of an SMTP spam-mill, because they lack the imagination to watch their own numbers and their spam rolls out unabated. This has been a ballooning problem for at least a year and a half. It's actually kinda inconvenient. Don't think they haven't been advised. Long before maverick-man coined the term "splog" I'd been sending my friends at the big G data on the extent of their problems. They know.
Dudes, go down the hall and ask the smart people at gmail how they do it. Now I have to go through the blogspot captcha gate instead of using ecto to post on their platform, hardly worth the bother.
Enough of the ironies and inconveniences. On the subject of ecto, please think kind thoughts for Adriaan. I am.
blogspot spam ecto splogs google technorati
( Jan 29 2006, 11:20:57 PM PST ) Permalink
Friday January 27, 2006
Beware the Tiger 10.4.4 Update I finally succumbed to Apple's pleas to update Tiger on my powerbook to 10.4.4. Maven was dumping hotspot errors and Eclipse was misbehaving, so an update seemed in order. Well, when the system came up, my menu bar items (clock, battery status, wifi status, speaker volume, etc) were gone! The network settings were goofed up and I had this profound flash of regret that I hadn't done a backup before doing the update.
Thankfully, Mike Hoover and davidx (co-horts at Technorati) were on hand to assist and dig up the following factoid:
- if you've disabled spotlight (yes I had, spotlight don't do nuffin' for me 'cept chew up resources), then the Tiger update may hose things
- The fix was to ditch
/System/Library/CoreServices/Search.bundle - What I did was open a shell and
sudo mv /System/Library/CoreServices/Search.bundle /var/tmp/, then rebooted - Menu bar came back and from the wifi pulldown, I was able to recreate my network settings
apple powerbook java eclipse maven macosx technorati
( Jan 27 2006, 11:39:48 AM PST ) Permalink
Thursday January 26, 2006
Test Dependencies versus Short Test Cycles A lightweight build system should be able to run a project's test harness quickly so that developers can validate their work and promptly move on to the next thing. Each test should, in theory, stand alone and not require the outcome of prior tests. But if testing the application requires setting up a lot of data to run against, the can run into a fundamental conflict with the practical. How does it go? "The difference between theory and practice is different in theory and in practice."
Recently I've been developing a caching subsystem that should support fixed size LRU's, expiration and so forth. I'd rather re-use the data that I already have in the other test's data set -- there are existing tests that exercise the data writer and reader classes. For my cache manager class, I started off the testing with a simple test case that creates a synthetic entity, a mock object, and validates that it can store and fetch as well as store and lazily expire the object. Great, that was easy!
What about the case of putting a lot of objects in the cache and expiring the oldest entries? What about putting a lot of objects in the cache and test fetching them while the expiration thread is concurrently removing expired entries? Testing the multi-threaded behavior is already a sufficient PITA, having to synthesize a legion of mock objects means more code to maintain -- elsewhere in the build system I have classes that the tests verify can access legions of objects, why not use that? The best code is the code that you don't have to maintain.
<sigh />
I want to be agile, I want to reuse and maintain less code and I want the test harness to run quickly. Is that too much to ask?
My take on this is that agile methodologies are composed of a set practices and principles that promote (among other things) flexible, confident and collaborative development. Working in a small startup, as I do at Technorati, all three are vital to our technical execution. I have a dogma about confidence:
- confidence
- Testing is where the rubber meets the road. Making a change and then putting your finger to the wind will not suffice. Internal improvement of the implementations, refactoring, are a thrice-hourly activity. Test driven development (TDD) is essential to confidently refactoring (internal implementations) and making alterations to the external interface. Serving this principle is a vital practice: automation. If testing consists of a finger to the wind, a manual process of walking through different client scenarios, it won't get done or it won't get done with sufficient thoroughness and the quality is guaranteed to lapse. Testing should come first (or, failing that, as early as possible), be automated and performed often, continuously. If tests are laborious and time consuming, guess what? People won't run them. And then you're back in wing-and-a-prayers-ville.
Lately I've been favoring maven for build management (complete with all of it's project lifecycle goodies). Maven gives me less build code to maintain (less build.xml stuff). However, one thing that's really jumped in my way is that in the project.xml file, there's only one way and one place to define how to run the tests. This is a problem that highlights one of the key tensions with TDD: from a purist standpoint, that's correct; there should be one test harness that runs each test case in isolation of the rest. But in my experience, projects usually have different levels of capability and integration that require a choice, either:
- the tests require their own data setup and teardown cycles, which my require a lot of time consuming data re-initialization ("drop the database tables if they exist", "create the database tables", "populate the database tables", "do stuff with the data")
- tests can be run in a predictable order with different known data states along the way
OR
I ended up writing an ant test runner that maven invokes after the database is setup. Each set of tests that transitions the data to a known state lays the ground work for the next set of tests. Perhaps I'd feel differently about it if I had more success with DBUnit or had a mock-object generator that could materialize classes pre-populated with desired data states. In the meantime, my test harness runs three times faster and there's less build plumbing (which is code) to maintain had I adhered to the TDD dogma.
ant maven tdd refactoring unit testing agile java technorati
( Jan 26 2006, 06:58:22 PM PST ) Permalink
Wednesday January 25, 2006
HTML in the Real World Google has a study of how HTML is really being used out in the wild. They've posted their results, Web Authoring Statistics
December 2005 we did an analysis of a sample of slightly over a billion documents, extracting information about popular class names, elements, attributes, and related metadata. The Good, The Bad and The Ugly: it's all in there.A billion documents sampled, nice!
I think this is a demonstration of Google's expanding interest in grokking the semantics of that are latent in document structures. The results are broken down by
- Pages and elements
- Elements and attributes
- Classes (class="")
- HTTP headers
- Page headers, head element contents
- Metadata, meta tag contents
- The body element
- Text elements
- Table elements
- Link relationships (rel/rev)
- The a element
- The img element
- Scripting: The <script> element
- Editors and their custom markup
I'd love to see how the data changes over time. I suspect parts of the web are becoming more orderly (web 2.0 applications are likely using well formed document structures) while the web as a whole is probably atrophying (the vast installation base of crappy or misconfigured tools are likely the preponderant generators of markup). I'm anticipating a lot of interesting data emerging as the ascendance of microformats continues. Goog, looking forward to follow-up surveys!
( Jan 25 2006, 06:37:29 AM PST ) Permalink
Tuesday January 17, 2006
Transparent Division of JDBC Reads and Writes in MySQL To scale the SQL query load on a database, it's a common practice to do writes to the master but query replication slaves for reads. If you're not sure what that's about and you have a pressing need to scale your MySQL query load, then stop what you're doing and buy Jeremy Zawodny's book High Performance MySQL.

When the state of the readOnly flag is flipped on the ReplicationConnection, it changes the connection accordingly. It will even load balance across multiple slaves. Where a normal JDBC connection to a MySQL database might look like this
Class.forName("com.mysql.jdbc.Driver");
Connection conn = DriverManager.
getConnection("jdbc:mysql://localhost/test", "scott", "tiger");
You'd connect with ReplicationDriver this way
ReplicationDriver driver = new ReplicationDriver();
Connection conn =
driver.connect("jdbc:mysql://master,slave1,slave2,slave3/test", props);
conn.setReadOnly(false);
// do stuff on the master
conn.setReadOnly(true);
// now do SELECTs on the slaves
and ReplicationDriver handles all of the magic of dispatching. The full deal is in the Connector/J docs, I was just pleased to finally find it!
I know of similar efforts in Perl like DBD::Multiplex and Class::DBI::Replication but I haven't had time or opportunity. Brad Fitzpatrick has discussed how LiveJournal handles connection management (there was a slide mentioning this at OSCON last August). LiveJournal definitely takes advantage of using MySQL as a distributed database but I haven't dug into LJ's code looking for it either. In the ebb and flow of my use Perl, it is definitely ebbing these days.
mysql database replication jdbc perl DBI
( Jan 17 2006, 11:42:09 PM PST ) Permalink
Sunday January 15, 2006
Surfacing Microformats in Firefox Calvin Yu has published his Tails Firefox Extension that will surface the microformats on a page, looks good! The plugin shows the hCals and hCards in a page, he's got a nice screenshot of the hCard renderings. Adding contacts (like Smartzilla) and events would be nice but the plugin could just point at the gateways for contacts and events on Technorati. BTW, for Firefox you can one-click install Technorati search in the browser search box on the Technorati Tools page.
microformats firefox technorati
( Jan 15 2006, 04:29:28 PM PST ) Permalink
Saturday January 14, 2006
Distributed Conversations with Microformats Last summer, Ryan King and Eran Globen blogged about citeVia and citeRel as a means of denoting conversation semantics between blog posts. A good summary and subsequent brainstorming is on the Microformats wiki. The blogosphere is currently rich with implicit distributed conversations. A little explicit microformat boost is, IMNSHO, exactly what's needed to nail the coffin in a lot of the crufty old centralized group systems (like Yahoo!'s and Google's). The future of virtual community is here and it is in conversing with blog posts.
There's a lot of discussion of primary citations and secondary props ("Via") but there's not as much on reply-to semantics except for in a few of Eran's posts. Isn't reply-to central to a conversation? Citations are more bibliographic (like when you're linking for a definition, a quote or to identify a source). On the other hand, conversations are about exchanged replies. This is as old as the Internet. Email clients put Reply-to headers in messages when you reply to them. RFC 850 defined it for NNTP over twenty years ago. Reply-to has been the binding for conversations for years, why stop now? That doesn't mean not to use cite and via, those are cool too but they're orthogonal to conversing and more pertinent to definition, quotation and source identification. I'm not entirely sure how I'd like to use via since it's kinda like citing a cite -- maybe it's not necessary at all. If you think of a via as a degenerative quote, then use quote. For instance, I think this makes sense (but then, I had a few glasses of wine earlier... I might not feel the same way in the morning):
I might agree that <a href="http://theryanking.com/blog/archives/2006/01/08/blogging-while-adult/" rel="reply-to">negative sarcasm</a> happens (and worse) wherever there is <a href="http://en.wikipedia.org/wiki/Anonymity" rel="cite">anonymity</a> it is one of an inductively provable aspect of human nature. Countless discussion boards have failed (and continue to) due to participant anonymity. However, it's also important to weigh in with the benefits of anonymity, would citizens of censored and oppressed societies be able to engage in progressive debate without it? Take a look at the Global Voices' <blockquote cite="http://joi.ito.com/archives/2005/05/23/second_draft_of_anonymous_blogging_guide.html"> <a href="http://cyber.law.harvard.eduglobalvoices/?p=179" rel="cite">Anonymous Blogging Guide</a</blockquote>.Wine bottle is corked now. Does that make sense?
distributedconversation microformats reply-to nntp yahoo google anonymity
( Jan 14 2006, 01:44:44 AM PST ) PermalinkBetter, Faster Technorati Blog Embed
Willie Dixon was built for comfort, Technorati embeds were built for speed!
Here's an inside tip: if you are a Technorati member and you claimed your blog a while ago, you can likely optimize how your Technorati embed is served and thus speed up how fast your page renders. Go to your account page for your first claimed blog (or go through them all one by one and click Configure Blog). Does the blog embed code match what's in your template? Load your blog page and View Source to compare. The old school embed code looked like this:
<script type="text/javascript" src="http://technorati.com/embed/[BLOG-CLAIM-ID].js"> </script>What you'll find on your account page is this:
<script type="text/javascript" src="http://embed.technorati.com/embed/[BLOG-CLAIM-ID].js"> </script>How is this an optimization? Why should you bother updating your blog template from the old to the new style? It's faster! We optimized serving the blog embeds with some additional infrastructure not too long ago. The old way works (built for comfort) but the new one works better (built for speed)!
technorati blog claim willie dixon speed comfort
( Jan 14 2006, 12:23:30 AM PST ) Permalink
Friday January 13, 2006
Technorati Is Hiring Technorati is hiring engineers for the website. You should be expert with PHP (including OO constructs, PEAR libraries, templating and application frameworks -- what works and what doesn't), savvy with XHTML and CSS -- be ready with referencable URLs to demonstrate, experienced with web 2.0 services (i.e. even if you don't blog you podcast or addictively use technorati, flickr, del.icio.us, digg, reddit, rollyo, squiddoo, etc) as well as having programmed in at least one language other than PHP and Javascript. Lotsa bonus points for using microformats and Ruby on Rails!
This position is full time, requires US work eligibility and is on-site (San Francisco, 3rd and Brannan). So, is it you? Check out the job listing and send your resume!
php technorati microformats rubyonrails xhtml css web20
( Jan 13 2006, 01:35:28 PM PST ) Permalink
Wednesday January 11, 2006
Google Earth on Mac OS X I'd played around on a Windows box with Google Earth a bit last summer and was both enamored with technology and saddened by the absence of Mac OS X support. Well, happy days are here again: a Mac version is out now!
The satellite definitely took new pictures of my neck of the woods, last time I'd checked you could see our car in the driveway of our house. Now there's a long shadow over it like they shot the picture very early in the morning, can't see the car but you can see the garbage cans (well, the resolution isn't that good, they look like little blips).
Thanks, G!
( Jan 11 2006, 08:48:32 PM PST ) Permalink
Tuesday January 10, 2006
Ramblings on the Tension between Simplicity and Extensibility There is widespread frustration with standards that try to boil the ocean of software problems that are out there to solve. Tim Bray has a sound advice:
If you're going to be designing a new XML language, first of all, consider not doing it.In his discussion of Minimalism vs. Completeness he quotes Gall's Law:
A complex system that works is invariably found to have evolved from a simple system that worked. A complex system designed from scratch never works and cannot be patched up to make it work. You have to start over with a working simple system.The tendency to inflate standards is similar to software development featuritus. I'm oft heard to utter the refrain, "Let's practice getting above the atmosphere before shooting for the moon." The scope of what is "complete" is likely to change 20% along the way towards getting there. The basic idea is to aim for sufficiency, not completeness; simplicity and extensibility are usually divergent. Part of the engineering art is to find as much of both as possible.
On the flip side, where completeness is an explicit upfront goal, there are internal tensions there as well. Either building for as many of the anticipated needs as possible or a profound commitment to refactoring has to be reckoned with. The danger of only implementing the simplist thing without a commitment to refactoring is that expediency tends to lead people, particularly if they haven't solved that type of problem before, to do the easy but counter-productive thing: taking short cuts, cutting and pasting and hard coding random magic doodads. As long as there is a commitment to refactoring, software atrophy can be combatted. Reducing duplication, separating concerns and coding to interfaces enables software to grow without declining in comprehensibility. Throw in a little test-driven development and you've got a lot of the standard shtick for agility.
Even though there's a project at work that I've been working on mostly solo, it's built for agility. The build system is relatively minimal thanks to maven. The core APIs and service interfaces (which favors simplicity: REST) are unit tested and the whole thing is monitored under CruiseControl to keep it all honest. This actually saved us the other day when a collaborator needed additional data included in the API's return values. He did the simplest thing (good) but I promptly got an email from CruiseControl that the build was broken. I reviewed his check-in and refactored it by moving the code that was put in-line in the method and moving it do it's own. I wrote a test for the method that fetches the additional data. And then wrote one for the original method's responses to include the additional data. The original method then acquired a flag to indicate whether the responses should be dressed up with this additional data; not all clients need it and it requires a round-trip to another data repository, making it a parameter makes sense since the applications that don't need it are performance sensitive. Afterwards, the code enjoyed additional benefits in that the caching had granularity that matched the distibution of the data sources. Getting the next mail from CruiseControl that it was happy with the build was very gratifying. I need to test-infect my colleagues so they learn to enjoy the same pavlovian response.
Anyway. I'm short on sleep and long on rambles this morning.
There are times when simple problems are mired in seemingly endless hand wringing and you have to stand up to shout JFDI. The Java software world, like RDF theorists and other parochial ivory tower clubs, seems to have a bad case of specificationitus. There are over 300 JSR's. Do we need all of those? On the other hand, great software is generally not created in a burst of a hackathon. There's no doubt that when a project has fallen into quicksand, getting all parties around a table and getting it out is an important way to clear the path. Rapid prototyping is often best accomplished in a focused push. I like prototyping to be used as a warm up exercise. If you can practice getting lift-off on a problem and you can attain high altitudes with some simple efforts, you're likelihood of making it to the moon increases.
agile refactoring technorati maven unit testing
( Jan 10 2006, 07:59:45 AM PST ) Permalink
Monday January 09, 2006
Claim Your Blog and Put Technorati Pinging On Your Browser Bookmark Bar A lot of people blog on platforms that don't ping for them. They could just use ecto, it'll help with the post formatting, tagging, media integration as well as pinging. One of the features for Technorati members is that the ping page will render a link to initiate a ping for each of the blogs you've claimed.
If your blog platform won't ping on your behalf, drag those links up to your bookmark bar and click them whenever you publish a new post. The world is changing all around us. When you post, you're part of that change. When you use Technorati, you can watch it change. Welcome to the Real Time Web!
( Jan 09 2006, 10:40:47 PM PST ) PermalinkOOM and HotSpot Bombs
Looks like I better hasten my effort to upgrade to Roller 2.x. This (v1.1) installation hit an OutOfMemoryError a little while ago and crashed the JVM in all of its hotspot glory. I'm suspicious of the caching implementation in Roller (IIRC, it's OSCache). For a non-clustered installation, plain-old-filesystem caches JFW. For distributed caches, JFW applies to memcached. We've been using the Java clients (and Perl and Python) for memcached productively for a long time now. Interestingly, some one was inspired to write a Java port of the memcached server. Crazy! And I think to myself, what a wonderful world.
( Jan 09 2006, 10:20:03 PM PST ) PermalinkMore Kudos
We must be doing something right. More kudos, this time from Jason Calacanis.
( Jan 09 2006, 12:46:48 AM PST ) Permalink
Sunday January 08, 2006
Kudo's For Technorati's Anti-Spam Effort Props from Jeremy on our anti-blog spam efforts are certainly appreciated. I know we don't have a spam-free index, however the amount of spam we keep out of the index is truly astonishing. Our ping interface is deluged with a torrent of rubbish but we do our best to scrub the nasty stuff out of our update stream. The problem defies conventional mail spam or even blog comment spam analytic techniques as the structure of blog spam is very different. Deep examination of the content and structure across a pattern of web sites is often required to distinguish it as spam but in the end, the indicators are there. Most spammers' publishing behaviors are statistical outliers by nature; the numbers speak for themselves.
We have a lot to do, on this and on many fronts but we try to pay attention to the gripes as a measure of priorities. The kudos are nice, too!
( Jan 08 2006, 08:29:31 PM PST ) Permalink


![[Valid RSS]](/images/valid-rss.png "Validate my RSS feed")