What's That Noise?! [Ian Kallen's Weblog]
 Saturday September 30, 2006
Saturday September 30, 2006
Publishing Little Bits: More than micropublishing, less than big bytes I find it really fascinating to see the acceptance of a publishing paradigm that lies in between the micropublishing realm of blogging, posting podcasts and videos and "old school" megapublishing. There are of course magazines; your typical piece in the New Yorker is longer than a blog post but shorter than a traditional book. But there's something else on the spectrum, for lack of a better term I'll call it minipublishing.
If you want to access expertise on a narrow topic, wouldn't it be cool to just get that, nothing more, nothing less? For instance, if you want to learn about the user permissions on Mac OS X, buy Brian Tanaka's Take Control of Permissions in Mac OS X. TidBITS Publishing has a whole catalog of narrowly focused publications that are bigger than a magazine article but smaller than your typical book. O'Reilly has gotten into the act too with their Short Cuts series. You can buy just enough on Using Microformats to get started; for ten bucks you get 45 pages of focused discussion of what microformats are and how to use them. Nothing more, nothing less. That's cool!
What if you could buy books in part or in serial form? Buy the introductory part or a specific chapter, if it seems well written, buy more. Many of us who've bought technical books are familiar with publish bloat, dozens of chapters across hundreds of pages that you buy even though you were probably only interested in a few chapters. Sure, sometimes publishers put a a few teaser chapters online hoping to entice you to buy the whole megilla. Works for me, I've definitely bought books after reading a downloaded PDF chapter. But I'm wondering now about buying just the chapters that I want.
publishing microformats macosx media micropublishing minipublishing
( Sep 30 2006, 07:04:31 PM PDT ) Permalink
Wednesday September 27, 2006
You Can't Handle The Truth
Colonel Jessup has assumed control of Newsweek:
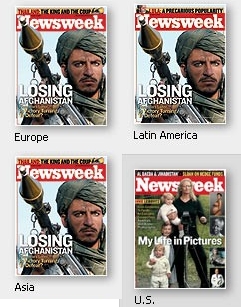
Ignorance is bliss
How meta:
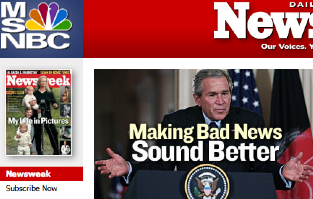
See ya at the gulag.
media newsweek ministry of truth afghanistan taliban bush
( Sep 27 2006, 04:16:31 PM PDT ) Permalink
Tuesday September 26, 2006
Green Data Centers At today's Intel Developer Forum, Google is presenting a paper that argues that the power supply standards that are built into today's PCs are anachronistic, inefficient and costly. With the maturing of the PC industry and horizontal scaling becoming a standard practice in data center deployments, it's time to say good-bye to these standards from the 1980's.
John Markoff reported in the NY Times today
The Google white paper argues that the opportunity for power savings is immense, by deploying the new power supplies in 100 million desktop PC's running eight hours a day, it will be possible to save 40 billion kilowatt-hours over three years, or more than $5 billion at California's energy rates.Nice to see Google taking leadership on the inefficiencies of the PC commodity hardware architectures. ( Sep 26 2006, 06:02:09 PM PDT ) Permalink
Google to Push for More Electrical Efficiency in PCs
Monday September 25, 2006
Greater than the sum of its parts The other week I reflected on the scaling-web-2.0 theme of the The Future of Web Apps workshop. Another major theme there was how social software is different, how transformative architectures of participation are. There was one talk that stood out from Tom Coates, Greater than the sum of its parts. A few days ago the slides were posted; I poked through 'em since and they jogged some memories loose, I thought I'd share Tom's message, late though it is, and embellish with my spin.
 Tom's basic thesis is that social software enables us to do "more together than we could apart" by "enhancing our social and collaborative abilities through structured mediation." Thinking about that, isn't web 1.0 about structured mediation? Centralized services, editors & producers, editorial staff & workflow, bean counting eyeballs, customer relationship management, demographic surveys and all of that crap? Yes, but what's different is that web 2.0 structured mediation is about bare sufficiency in that it's better to have too little than too much, the software should get out of the way of the user, make him/her a participant, not lead him/her around by the nose.
Tom's basic thesis is that social software enables us to do "more together than we could apart" by "enhancing our social and collaborative abilities through structured mediation." Thinking about that, isn't web 1.0 about structured mediation? Centralized services, editors & producers, editorial staff & workflow, bean counting eyeballs, customer relationship management, demographic surveys and all of that crap? Yes, but what's different is that web 2.0 structured mediation is about bare sufficiency in that it's better to have too little than too much, the software should get out of the way of the user, make him/her a participant, not lead him/her around by the nose.
Next, Tom highlighted that valuable social software should serve
- Individual Motives
- An individual should get value from their contribution
- Social Value
- The individual's contributions should provide value to their peers as well
- Business/Organizational Value
- The organization that hosts the service should enable the user to create and share value and then derive aggregate value to expose this back to it users. I thought that was really well considered.
- anticipate reciprocity
- by offering value, it's reasonable to expect others to contribute value as well
- reputation
- by showing off a little, highlighting something uniquely yours to contribute, you gain prestige
- sense of efficacy
- by being able to make an impact, a sense of worth is felt
- identification with a group
- be it for altruism or attachment, contributing to a group makes you part of it
Citing The Success of Open Source , he likened social software participants motivations to this ranked list of open source contributor's motivations
- learning to code
- gaining reputation
- scratching an itch
- contributing to the commons
- sticking it to Microsoft (well, probably no analog in that motive for participating in social software ...)
Here are some social software "best practices":
- Expose every axis of data you can every axis of data is an application opportunity
- Give people a place to represent themselves
- these are my bookmarks
- these are my photos
- these are my videos
- here is my voice
- Allow them to associate, connect and form relations with one another
- Help them annotate, rate and comment... on Digg, every action is a form of self expression
- Look for ways to expose this data back onto the site
- Be wary of how money changes everything; points, votes and competition can distort the social values as well
- Be very careful of user expectations around how private or public their contribution is
- Be wary of creating monocultures or echo chambers
- Attention and advertising
- Premium accounts
- Building services around the data
- Using user-generated annotations and contributions to improve your other services
futureofwebapps-sf06 social software virtual community
( Sep 25 2006, 10:24:40 AM PDT ) Permalink
Thursday September 21, 2006
Community Policing In The Blogosphere I mused about people-powered topic classification for blogs after playing with the Google Image Labeller the other week. It seems like a doable feature for Technorati because the incentives to game topic classification are low.
 That same week, Rafe posed a question about community driven spam classification:
That same week, Rafe posed a question about community driven spam classification:
Why couldn't Blogger or Six Apart or a firm like Technorati add all of the new blogs they register to a queue to be examined using Amazon's Mechanical Turk service? I'd love to see someone at least do an experiment in this vein. The only catch is that you'd want to have each blog checked more than once to prevent spiteful reviewers from disqualifying blogs that they didn't agree with.The catch indeed is that the incentive is high for a system like this to be gamed. Shortly after blogger implemented their flag, spammers
(read the rest)
"Bloggerbowling" - the practice of having robots flag multiple random blogs as splogs regardless of content to degrade the accuracy of the policing service.As previously cited from Cory, all complex ecosystems have parasites. So I've been thinking about what it would take to do this effectively, what would it take overcome the blogosphere's parasites bloggerbowling efforts? The things that come to mind for any system of community policing are about rewards and obstacles. For example
- Leverage a user's reputation to weight the value of his/her vote, Technorati's authority ranking (based on the count of unique blogs linking to a blog over 180 days) would be an example of reputation
- Raise the barrier for abuse by requiring participants to develop karma over time before they can vote
- Create incentives for participation beyond answering "this search had a load of crap in it, how can I clear it out of the way?" (most Technorati users toggle the authority filter)
- Instrument the system to ferret out the usage statistics, the actions of obvious 'bowlers would have to be automatically discarded
- Support administrative intervention, staff would have to be watching the detectives
At the end of the day, I don't have the answers. But I think Rafe, Doc and so many others concerned with splog proliferation are asking great questions. Technorati is currently keeping a tremendous volume of spam out of its search results but, at the end of the day, there's still much to do. And this post is the end of my day, today.
spam splog splogs technorati virtual community blogs web spam
( Sep 21 2006, 11:06:22 PM PDT ) Permalink
Wednesday September 13, 2006
Everybody Hurts, Sometimes A few weeks ago, Adam mentioned some of the shuffling going on at Technorati's data centers. Yep, we've had our share of operational instability lately, when you have systems that expect consistent network topologies and that has to change, I suppose these things will happen. It seems a common theme I keep hearing in conversations and presentations about web based services: the growing pains.
 This morning, Kevin Rose discussed The digg story: from one idea to nine million page views at The Future of Web Apps workshop. Digg has had to overcome a lot of the "normal" problems (MySQL concurrency, data set growth, etc) that growing web services face and have turned to some of the usual remedies, rethinking the data constructs (they hired DBA's) and memcached. This afternoon, Tantek was in fine form discussing web development practices with microformats where he announced updates to the search system Technorati's been cooking, again a growth induced revision. Shortly thereafter, I enjoyed the stats and facts that Steve Olechowski presented in his 10 things you didn't know about RSS talk. And so it goes, this evening it was Feedburner having an episode. "me" time -- heh, know how ya feel <g>
This morning, Kevin Rose discussed The digg story: from one idea to nine million page views at The Future of Web Apps workshop. Digg has had to overcome a lot of the "normal" problems (MySQL concurrency, data set growth, etc) that growing web services face and have turned to some of the usual remedies, rethinking the data constructs (they hired DBA's) and memcached. This afternoon, Tantek was in fine form discussing web development practices with microformats where he announced updates to the search system Technorati's been cooking, again a growth induced revision. Shortly thereafter, I enjoyed the stats and facts that Steve Olechowski presented in his 10 things you didn't know about RSS talk. And so it goes, this evening it was Feedburner having an episode. "me" time -- heh, know how ya feel <g>
 While Feedburner gets "me" time, Flickr gets massages when they have system troubles. Speaking of Flickr, I'm looking forward to Cal Henderson's talk, Taking Flickr from Beta to Gamma at tomorrow's session of The Future of Web Apps. I caught a bit of Scaling Fast and Cheap - How We Built Flickr last spring, Cal knows the business. I've been meaning to check out his book, Building Scalable Web Sites.
While Feedburner gets "me" time, Flickr gets massages when they have system troubles. Speaking of Flickr, I'm looking forward to Cal Henderson's talk, Taking Flickr from Beta to Gamma at tomorrow's session of The Future of Web Apps. I caught a bit of Scaling Fast and Cheap - How We Built Flickr last spring, Cal knows the business. I've been meaning to check out his book, Building Scalable Web Sites.
Perhaps everybody needs a therapeutic message for the times of choppy seas. When Technorati hurts, it just seems to hurt. Should it be getting meditation and tiger balm (hrm, smelly)? Some tickling and laughter (don't operate heavy machinery)? Animal petting (could be smelly)? Aromatherapy (definitely smelly)? Data center feng shui? Gregorian chants? R.E.M. samples?
futureofwebapps-sf06 palaceoffinearts flickr feedburner digg technorati microformats memcached
( Sep 13 2006, 09:26:42 PM PDT ) Permalink
Monday September 04, 2006
Applying Security Tactics to Web Spam
 Hey, I'm in Wired! The current Wired has an article about blog spam by Charles Mann that includes a little bit of my conversation with him. Spam + Blogs = Trouble covers a lot of the issues facing blog publishers (and in a broader sense,
Hey, I'm in Wired! The current Wired has an article about blog spam by Charles Mann that includes a little bit of my conversation with him. Spam + Blogs = Trouble covers a lot of the issues facing blog publishers (and in a broader sense, user generated content participant created artifacts in general). There are some particular challenges faced by services like Technorati that index these goods in real time; not only must our indices have very fast cycles, so must our abilities to keep the junk out. I was in good company amongst Mann's sources, he talked to a variety of folks from many sides of the blog spam problem: Dave Sifry, Jason Goldman, Anil Dash, Matt Mullenweg, Natalie Glance and even some blog spam perps.
I've also had a lot of conversations with Doc lately about blog spam and the problems he's been having with kleptotorial. A University of Maryland study of December 2005 pings on weblogs.com determined that 75% of the pings are spam AKA spings. By excluding the non-English speaking blogosphere and not taking into account the large portions of the blogosphere that don't ping weblogs.com, that study ignored a larger blogosphere but overall, that assessment of the ping stream coming from weblogs.com seemed pretty accurate. As Dave reported last month, by last July we were finding over 70% of the pings coming into Technorati to be spam.
Technorati has deployed a number of anti-spam measures (such as targetting specific Blogger profiles, as Mitesh Vasa has. Of coures there's more that we've done but if I told you I'd have to kill you, sorry). There are popular theories in circulation on how to combat web spam involving blacklists of URLs and text analysis but those are just little pieces of the picture. Of the things I've seen from the anti-splog crusader websites, I think the fighting splog blog has hit one of the key vulnerabilities of splogs: they're just in it to get paid. So, hit 'em in the wallet. In particular, splog fighter's (who is that masked ranger?) targetting of AdSense's Terms of Service violators sounds most promising. Of course, there's more to blog spam than AdSense, Blogger and pings. The thing gnawing at me about all of these measures is their reactiveness. The web is a living organism of events, the tactics to keeping trashy intrusions out should be event driven too.
Intrusion detection is a proven tool in the computer security practice. System changes are a distrurbance in the force, significant events that should trigger attention. Number one in the list of The Six Dumbest Ideas in Computer Security is "Default Permit." I remember the days when you'd take a host out of the box from Sun or SGI (uh, who?) and it would come up in "rape me" mode. Accounts with default passwords, vulnerability laden printing daemons, rsh, telnet and FTP (this continued even long after the arrival of ssh and scp), all kinds of superfluous services in /etc/inetd.conf and so on. The first order of business was to "lock down" the host by overlaying a sensible configuration. The focus on selling big iron (well, bigger than a PC) into the enterprise prevented vendors from seeing the bigger opportunity in internet computing and the web. And so reads the epitaph of old-school Unix vendors (well, in Sun's case Jonathan Schwartz clearly gets it -- reckoning with the "adapt or die" options, he's made the obvious choice). Those of us building public facing internet services had to take the raw materials from the vendor and "fix them". The Unix vendors really blew it in so many ways, it's really too bad. The open source alternatives weren't necessarily doing it better, even the Linux distros of the day had a lot of stupid defaults. The BSD's did a better job but, unless you were Yahoo! or running an ISP, BSD didn't matter (well, I used FreeBSD very successfully in 90's but then I do things differently). Turning on access to everything but keeping out the bad guys by selectively reacting to vulnerabilities is an unwinnable game. When it comes to security matters, the power of defaults can be the harbinger of doom.
The "Default Deny" approach is to explicitly prescribe what services to turn on. It's the obvious, sensible approach to putting hosts on a public network. By having very tightly defined criteria for what packets are allowed to pass, watching for adversarial connections is greatly simplified. I've been thinking a lot about how this could be applied to providing services such as web search while also keeping the bad guys (web spammers) out.
Amongst web indexers, the big search services try to cast the widest net to achieve the broadest coverage. Remember the mine is bigger than yours flap? Search indices seemingly follow a Default Permit policy. On the other extreme from "try to index everything" is "only index the things that I prescribe." This "size isn't everything" response is seen in services like Rollyo. You can even use Alexa Web Search Platform to cobble your own index. But unlike the case of computer security stances, with web search you want opportunities for serendipity; searching within a narrowly prescribed subset of the web greatly limits those opportunities. Administratively managed Default Deny policies will only get you so far. I suspect in the future effective web indexing is going to require more detailed classification, a Default Deny with algorithmic qualification to allow. Publishers will have to earn their way into the search indices through good behavior.
The blogosphere has thrived on openness and ease of entry but indeed, all complex ecosystems have parasites. So, while we're grateful to be in a successful ecosystem, we'd all agree that we have to be vigilant about keeping things tidy. The junk that the bad guys want to inject into the update stream has to be filtered out. I think the key to successful web indexing is to cast a wide net , keep tightly defined criteria for deciding what gets in and to use event driven qualification to match the criteria. The attention hi-jackers need to be suppressed and the content that would be misappropriated has to be respected. This can be done by deciding that whatever doesn't meet the criteria for indexing, should be kept out. Not that we have to bid adieu to the yellow brick road of real time open content but perhaps we do have to setup checkpoints and rough up the hooligans who soil the vistas.
spam web spam splog splogs adsense technorati wired
( Sep 04 2006, 11:10:15 PM PDT ) Permalink
Saturday September 02, 2006
Mechanical Turk Tagging I spent way too much time last night giving Google some free labor. The Google Image Labeler is kinda fun, in a peculiar way. In 90 second stretches that AJAX-ishly links you to someone else out there in the ether, you are shown images and a text box to enter tags ("labels" is apparently Google's preferred term, whatever). Each time you get a match with your anonymous partner, you get 100 points. The points are like the ones on Whose Line Is It Anyway, they don't matter. And yet it was strangely fun. The most I ever got in any one 90 second session was 300 points. Network latency was the biggest constraint, sometimes Google's image loading was slow. Also, the images are way too small on my Powerbook ... this is the kinda thing you want a Cinema Display for (the holidays are coming, now you know what to get me).
So what if Technorati did this? Suppose you and some anonymous cohort could be simultaneously shown a blog post and tag it. Most blogging platforms these days support categories. But there are a lot of blog posts out there that might benefit from further categorization. Author's are already tagging their posts and blog readers can already tag their favorite blogs but enabling an ESP game with blog posts sounds like an intriguing way to refine categorization of blogs and posts.
tagging esp game google image labeler mechanical turk
( Sep 02 2006, 12:31:26 PM PDT ) Permalink


![[Valid RSS]](/images/valid-rss.png "Validate my RSS feed")